原创文章,转载请务必将下面这段话置于文章开头处(保留超链接)。
本文转发自技术世界,原文链接 http://www.jasongj.com/sql/cte/
CTE or WITH
WITH语句通常被称为通用表表达式(Common Table Expressions)或者CTEs。
WITH语句作为一个辅助语句依附于主语句,WITH语句和主语句都可以是SELECT,INSERT,UPDATE,DELETE中的任何一种语句。
例讲CTE
WITH语句最基本的功能是把复杂查询语句拆分成多个简单的部分,如下例所示1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17WITH regional_sales AS (
SELECT region, SUM(amount) AS total_sales
FROM orders
GROUP BY region
), top_regions AS (
SELECT region
FROM regional_sales
WHERE total_sales > (SELECT SUM(total_sales)/10 FROM regional_sales
)
SELECT
region,
product,
SUM(quantity) AS product_units,
SUM(amount) AS product_sales
FROM orders
WHERE region IN (SELECT region FROM top_regions)
GROUP BY region, product;
该例中,定义了两个WITH辅助语句,regional_sales和top_regions。前者算出每个区域的总销售量,后者了查出所有销售量占所有地区总销售里10%以上的区域。主语句通过将这个CTEs及订单表关联,算出了顶级区域每件商品的销售量和销售额。
当然,本例也可以不使用CTEs而使用两层嵌套子查询来实现,但使用CTEs更简单,更清晰,可读性更强。
在WITH中使用数据修改语句
文章开头处提到,WITH中可以不仅可以使用SELECT语句,同时还能使用DELETE,UPDATE,INSERT语句。因此,可以使用WITH,在一条SQL语句中进行不同的操作,如下例所示。1
2
3
4
5
6
7
8
9WITH moved_rows AS (
DELETE FROM products
WHERE
"date" >= '2010-10-01'
AND "date" < '2010-11-01'
RETURNING *
)
INSERT INTO products_log
SELECT * FROM moved_rows;
本例通过WITH中的DELETE语句从products表中删除了一个月的数据,并通过RETURNING子句将删除的数据集赋给moved_rows这一CTE,最后在主语句中通过INSERT将删除的商品插入products_log中。
如果WITH里面使用的不是SELECT语句,并且没有通过RETURNING子句返回结果集,则主查询中不可以引用该CTE,但主查询和WITH语句仍然可以继续执行。这种情况可以实现将多个不相关的语句放在一个SQL语句里,实现了在不显式使用事务的情况下保证WITH语句和主语句的事务性,如下例所示。1
2
3
4
5
6
7
8WITH d AS (
DELETE FROM foo
),
u as (
UPDATE foo SET a = 1
WHERE b = 2
)
DELETE FROM bar;
WITH使用注意事项
- WITH中的数据修改语句会被执行一次,并且肯定会完全执行,无论主语句是否读取或者是否读取所有其输出。而WITH中的SELECT语句则只输出主语句中所需要记录数。
- WITH中使用多个子句时,这些子句和主语句会并行执行,所以当存在多个修改子语句修改相同的记录时,它们的结果不可预测。
- 所有的子句所能“看”到的数据集是一样的,所以它们看不到其它语句对目标数据集的影响。这也缓解了多子句执行顺序的不可预测性造成的影响。
- 如果在一条SQL语句中,更新同一记录多次,只有其中一条会生效,并且很难预测哪一个会生效。
- 如果在一条SQL语句中,同时更新和删除某条记录,则只有更新会生效。
- 目前,任何一个被数据修改CTE的表,不允许使用条件规则,和ALSO规则以及INSTEAD规则。
WITH RECURSIVE
WITH语句还可以通过增加RECURSIVE修饰符来引入它自己,从而实现递归
WITH RECURSIVE实例
WITH RECURSIVE一般用于处理逻辑上层次化或树状结构的数据,典型的使用场景是寻找直接及间接子结点。
定义下面这样的表,存储每个区域(省、市、区)的id,名字及上级区域的id1
2
3
4
5
6CREATE TABLE chinamap
(
id INTEGER,
pid INTEGER,
name TEXT
);
需要查出某个省,比如湖北省,管辖的所有市及市辖地区,可以通过WITH RECURSIVE来实现,如下1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19WITH RECURSIVE result AS
(
SELECCT
id,
name
FROM chinamap
WHERE id = 11
UNION ALL
SELECT
origin.id,
result.name || ' > ' || origin.name
FROM result
JOIN chinamap origin
ON origin.pid = result.id
)
SELECT
id,
name
FROM result;
结果如下1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19 id | name
-----+--------------------------
11 | 湖北省
110 | 湖北省 > 武汉市
120 | 湖北省 > 孝感市
130 | 湖北省 > 宜昌市
140 | 湖北省 > 随州市
150 | 湖北省 > 仙桃市
160 | 湖北省 > 荆门市
170 | 湖北省 > 枝江市
180 | 湖北省 > 神农架市
111 | 湖北省 > 武汉市 > 武昌区
112 | 湖北省 > 武汉市 > 下城区
113 | 湖北省 > 武汉市 > 江岸区
114 | 湖北省 > 武汉市 > 江汉区
115 | 湖北省 > 武汉市 > 汉阳区
116 | 湖北省 > 武汉市 > 洪山区
117 | 湖北省 > 武汉市 > 青山区
(16 rows)
WITH RECURSIVE 执行过程
从上面的例子可以看出,WITH RECURSIVE语句包含了两个部分
- non-recursive term(非递归部分),即上例中的union all前面部分
- recursive term(递归部分),即上例中union all后面部分
执行步骤如下
- 执行non-recursive term。(如果使用的是union而非union all,则需对结果去重)其结果作为recursive term中对result的引用,同时将这部分结果放入临时的working table中
- 重复执行如下步骤,直到working table为空:用working table的内容替换递归的自引用,执行recursive term,(如果使用union而非union all,去除重复数据),并用该结果(如果使用union而非union all,则是去重后的结果)替换working table
以上面的query为例,来看看具体过程
1.执行1
2
3
4
5SELECT
id,
name
FROM chinamap
WHERE id = 11
结果集和working table为1
11 | 湖北
2.执行1
2
3
4
5
6SELECT
origin.id,
result.name || ' > ' || origin.name
FROM result
JOIN chinamap origin
ON origin.pid = result.id
结果集和working table为1
2
3
4
5
6
7
8110 | 湖北省 > 武汉市
120 | 湖北省 > 孝感市
130 | 湖北省 > 宜昌市
140 | 湖北省 > 随州市
150 | 湖北省 > 仙桃市
160 | 湖北省 > 荆门市
170 | 湖北省 > 枝江市
180 | 湖北省 > 神农架市
3.再次执行recursive query,结果集和working table为1
2
3
4
5
6
7111 | 湖北省 > 武汉市 > 武昌区
112 | 湖北省 > 武汉市 > 下城区
113 | 湖北省 > 武汉市 > 江岸区
114 | 湖北省 > 武汉市 > 江汉区
115 | 湖北省 > 武汉市 > 汉阳区
116 | 湖北省 > 武汉市 > 洪山区
117 | 湖北省 > 武汉市 > 青山区
4.继续执行recursive query,结果集和working table为空
5.结束递归,将前三个步骤的结果集合并,即得到最终的WITH RECURSIVE的结果集
严格来讲,这个过程实现上是一个迭代的过程而非递归,不过RECURSIVE这个关键词是SQL标准委员会定立的,所以PostgreSQL也延用了RECURSIVE这一关键词。
WITH RECURSIVE 防止死循环
从上一节中可以看到,决定是否继续迭代的working table是否为空,如果它永不为空,则该CTE将陷入无限循环中。
对于本身并不会形成循环引用的数据集,无段作特别处理。而对于本身可能形成循环引用的数据集,则须通过SQL处理。
一种方式是使用UNION而非UNION ALL,从而每次recursive term的计算结果都会将已经存在的数据清除后再存入working table,使得working table最终会为空,从而结束迭代。
然而,这种方法并不总是有效的,因为有时可能需要这些重复数据。同时UNION只能去除那些所有字段都完全一样的记录,而很有可能特定字段集相同的记录即应该被删除。此时可以通过数组(单字段)或者ROW(多字段)记录已经访问过的记录,从而实现去重的目的。
WITH RECURSIVE 求最短路径
定义无向有环图如下图所示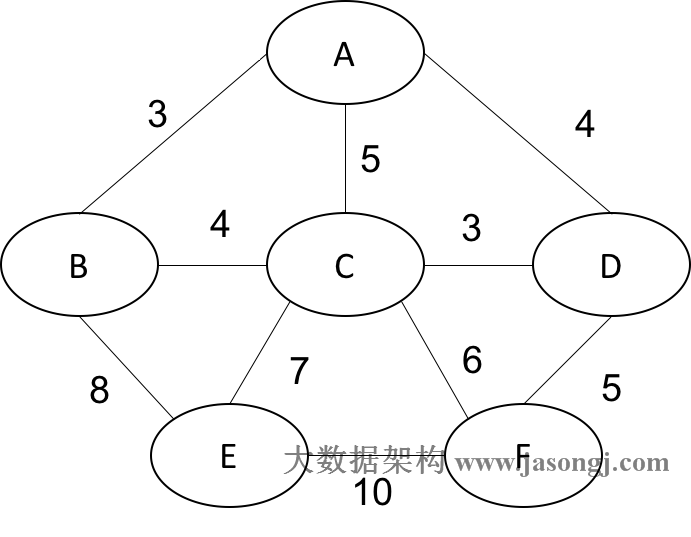
定义如下表并存入每条边的权重1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17CREATE TABLE graph
(
id char,
neighbor char,
value integer
);
INSERT INTO graph
VALUES('A', 'B', 3),
('A', 'C', 5),
('A', 'D', 4),
('B', 'E', 8),
('B', 'C', 4),
('E', 'C', 7),
('E','F', 10),
('C', 'D', 3),
('C', 'F', 6),
('F','D', 5);
计算思路如下:
- 因为是无向图,所以首先要将各条边的id和neighbor交换一次以方便后续计算。
- 利用WITH RECURSIVE算出所有可能的路径并计算其总权重。
- 因为该图有环,为避免无限循环,同时为了计算路径,将经过的结点存于数据中,当下一个结点已经在数据中时,说明该结点已被计算。
- 最终可算出所有可能的路径及其总权重
实现如下1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35 WITH RECURSIVE edges AS (
SELECT id, neighbor, value FROM graph
UNION ALL
SELECT neighbor, id, value
FROM graph
),
all_path (id, neighbor, value, path, depth, cycle) AS (
SELECT
id, neighbor, value, ARRAY[id], 1, 'f'::BOOLEAN
FROM edges
WHERE id = 'A'
UNION ALL
SELECT
all_path.id,
edges.neighbor,
edges.value + all_path.value,
all_path.path || ARRAY[edges.id],
depth + 1,
edges.id = ANY(all_path.path)
FROM edges
JOIN all_path
ON all_path.neighbor = edges.id
AND NOT cycle
), a_f AS (
SELECT
rank() over(order by value) AS rank,
path || neighbor AS path,
value,
depth
FROM all_path
WHERE neighbor = 'F'
)
SELECT path, value, depth
FROM a_f
WHERE rank = 1;
WITH RECURSIVE 使用限制
- 如果在recursive term中使用LEFT JOIN,自引用必须在“左”边
- 如果在recursive term中使用RIGHT JOIN,自引用必须在“右”边
- recursive term中不允许使用FULL JOIN
- recursive term中不允许使用GROUP BY和HAVING
- 不允许在recursive term的WHERE语句的子查询中使用CTE的名字
- 不支持在recursive term中对CTE作aggregation
- recursive term中不允许使用ORDER BY
- LIMIT / OFFSET不允许在recursive term中使用
- FOR UPDATE不可在recursive term中使用
- recursive term中SELECT后面不允许出现引用CTE名字的子查询
- 同时使用多个CTE表达式时,不允许多表达式之间互相访问(支持单向访问)
- 在recursive term中不允许使用FOR UPDATE
CTE 优缺点
- 可以使用递归 WITH RECURSIVE,从而实现其它方式无法实现或者不容易实现的查询
- 当不需要将查询结果被其它独立查询共享时,它比视图更灵活也更轻量
- CTE只会被计算一次,且可在主查询中多次使用
- CTE可极大提高代码可读性及可维护性
- CTE不支持将主查询中where后的限制条件push down到CTE中,而普通的子查询支持


