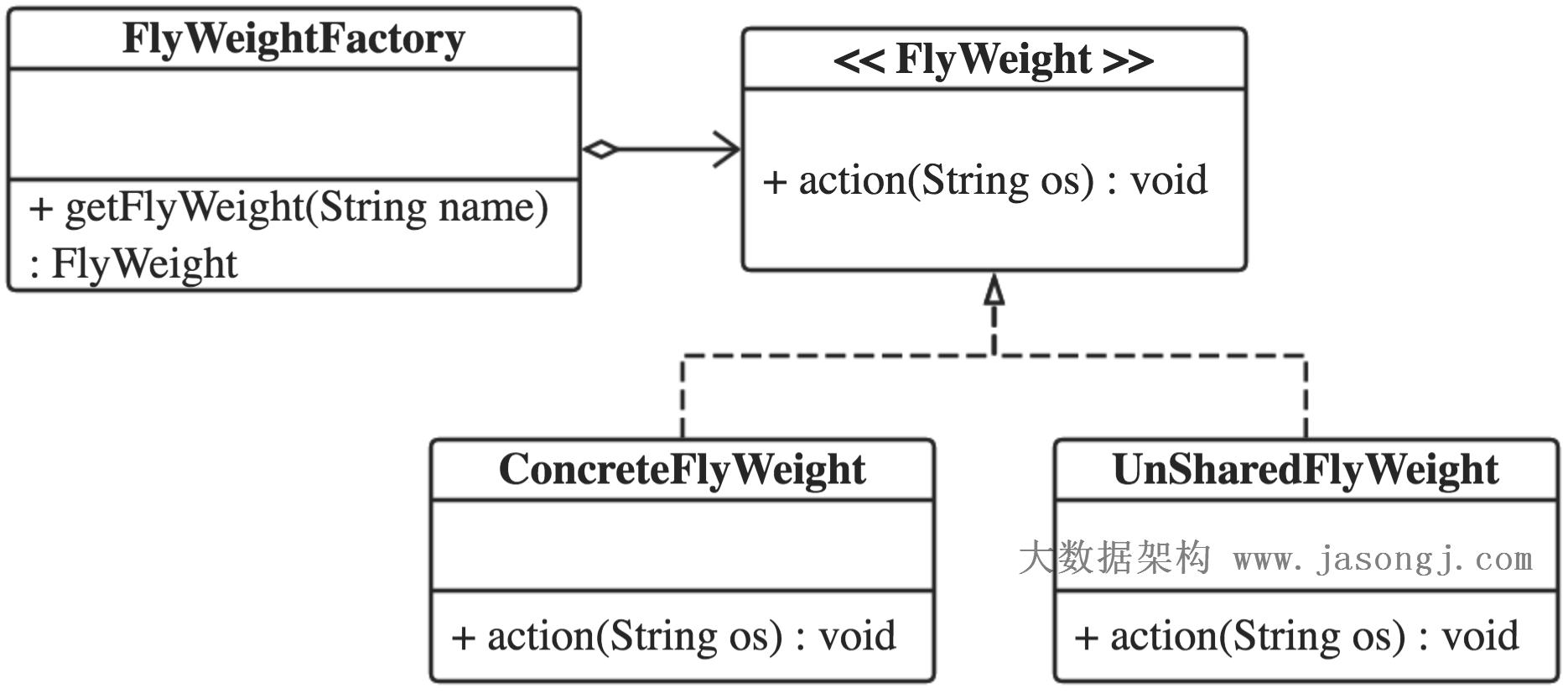
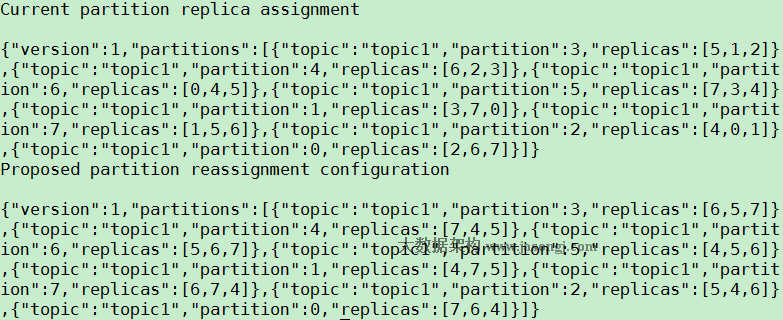
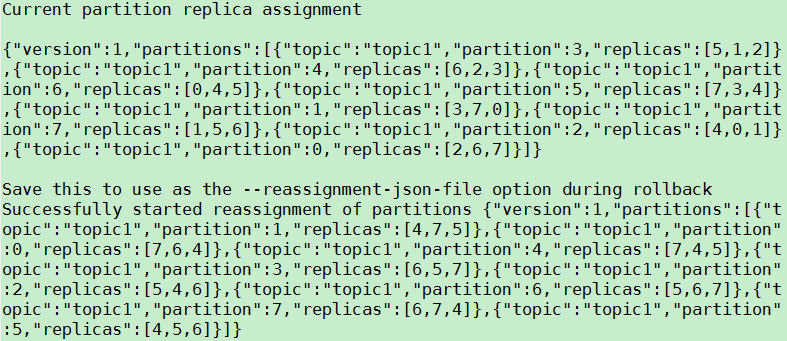
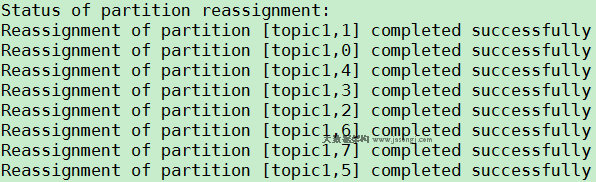
原创文章,转载请务必将下面这段话置于文章开头处。
本文转发自技术世界,原文链接 http://www.jasongj.com/spark/adaptive_execution/
本文所述内容均基于 2018年9月17日 Spark 最新 Spark Release 2.3.1 版本,以及截止到 2018年10月21日 Adaptive Execution 最新开发代码。自动设置 Shuffle Partition 个数已进入 Spark Release 2.3.1 版本,动态调整执行计划与处理数据倾斜尚未进入 Spark Release 2.3.1
1 背景
前面《Spark SQL / Catalyst 内部原理 与 RBO》与《Spark SQL 性能优化再进一步 CBO 基于代价的优化》介绍的优化,从查询本身与目标数据的特点的角度尽可能保证了最终生成的执行计划的高效性。但是
- 执行计划一旦生成,便不可更改,即使执行过程中发现后续执行计划可以进一步优化,也只能按原计划执行
- CBO 基于统计信息生成最优执行计划,需要提前生成统计信息,成本较大,且不适合数据更新频繁的场景
- CBO 基于基础表的统计信息与操作对数据的影响推测中间结果的信息,只是估算,不够精确
本文介绍的 Adaptive Execution 将可以根据执行过程中的中间数据优化后续执行,从而提高整体执行效率。核心在于两点
- 执行计划可动态调整
- 调整的依据是中间结果的精确统计信息
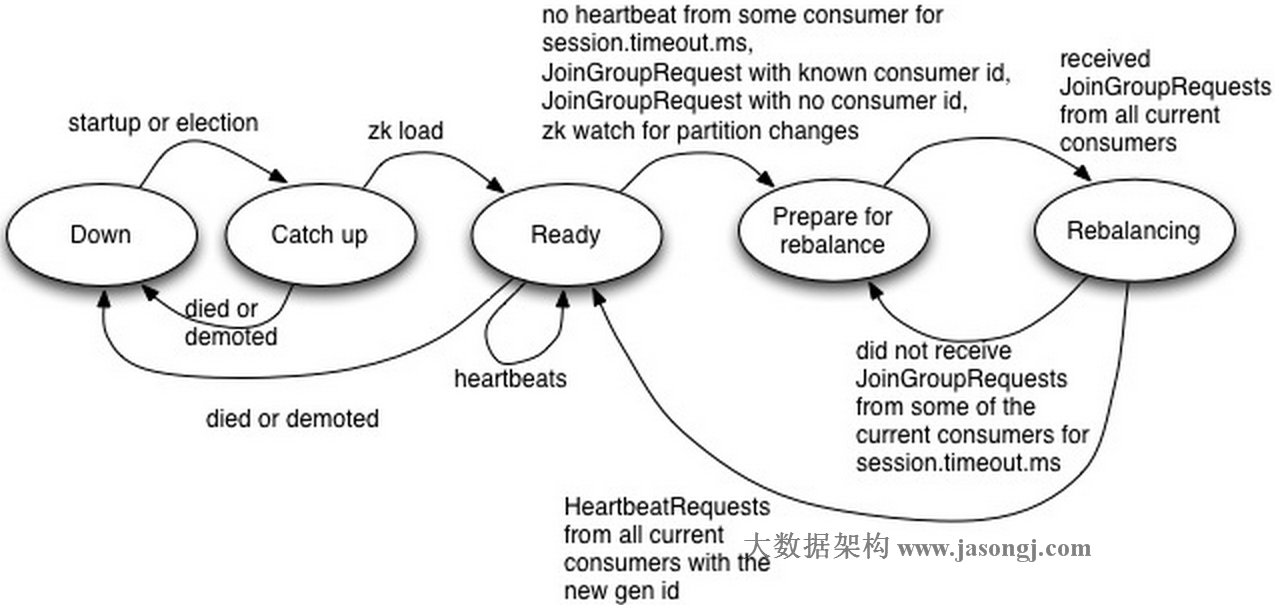
2 动态设置 Shuffle Partition
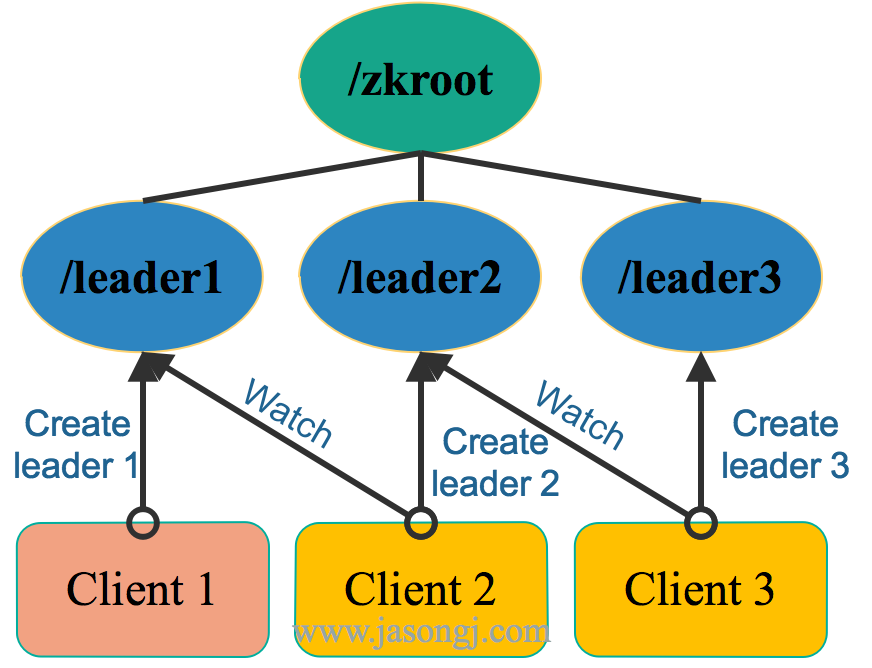
2.1 Spark Shuffle 原理
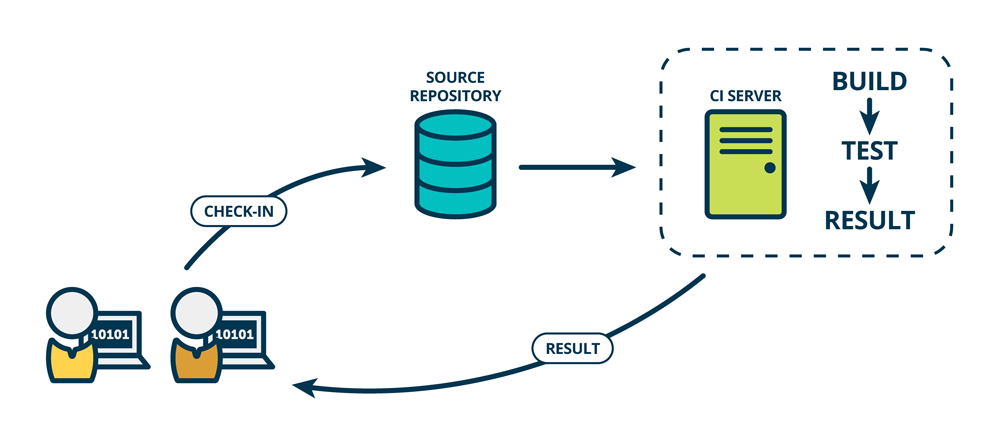
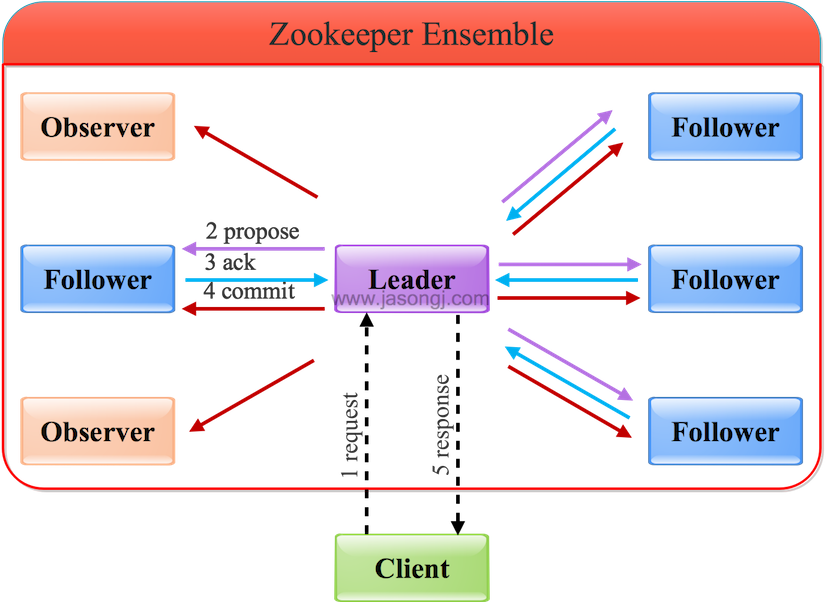
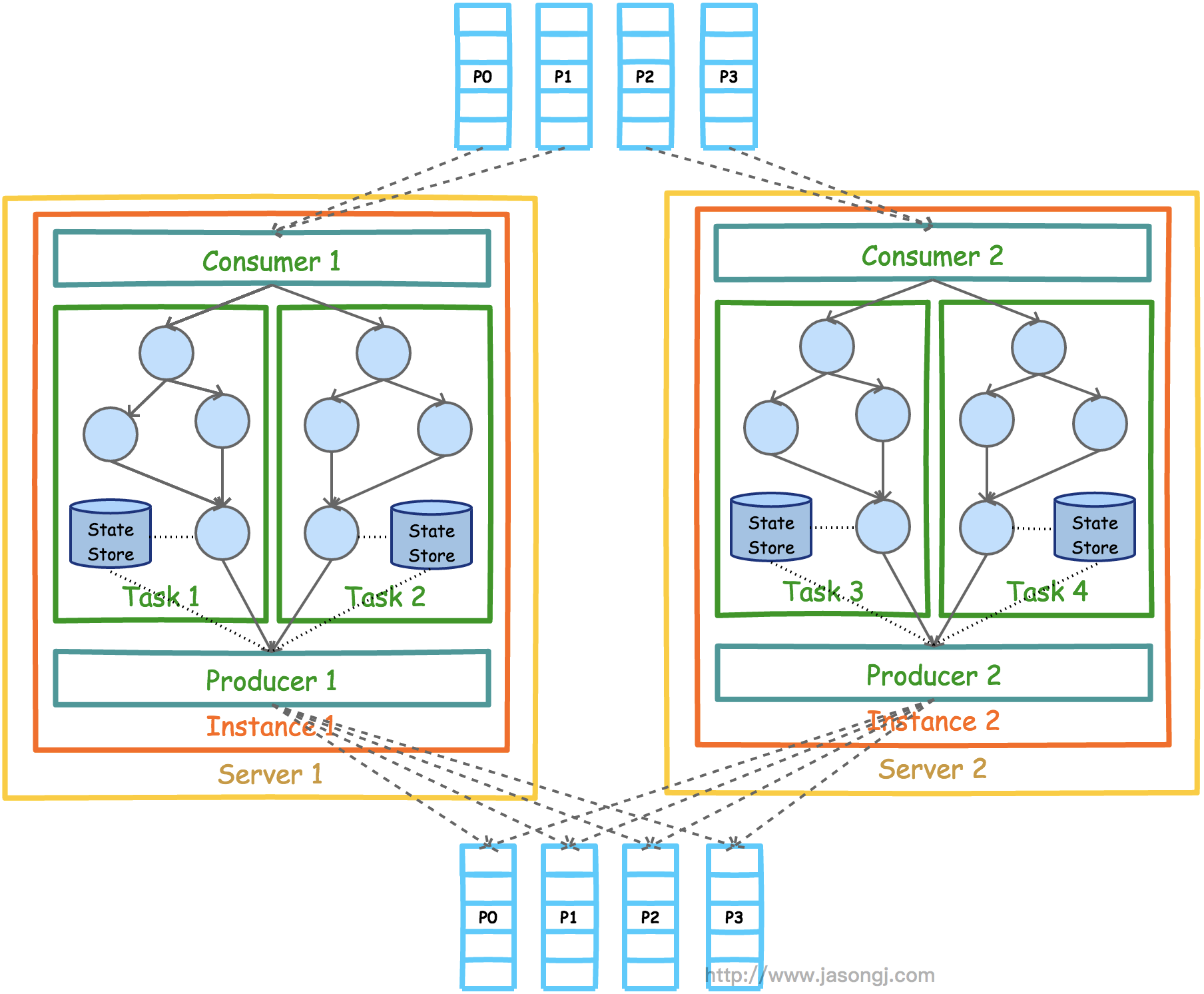
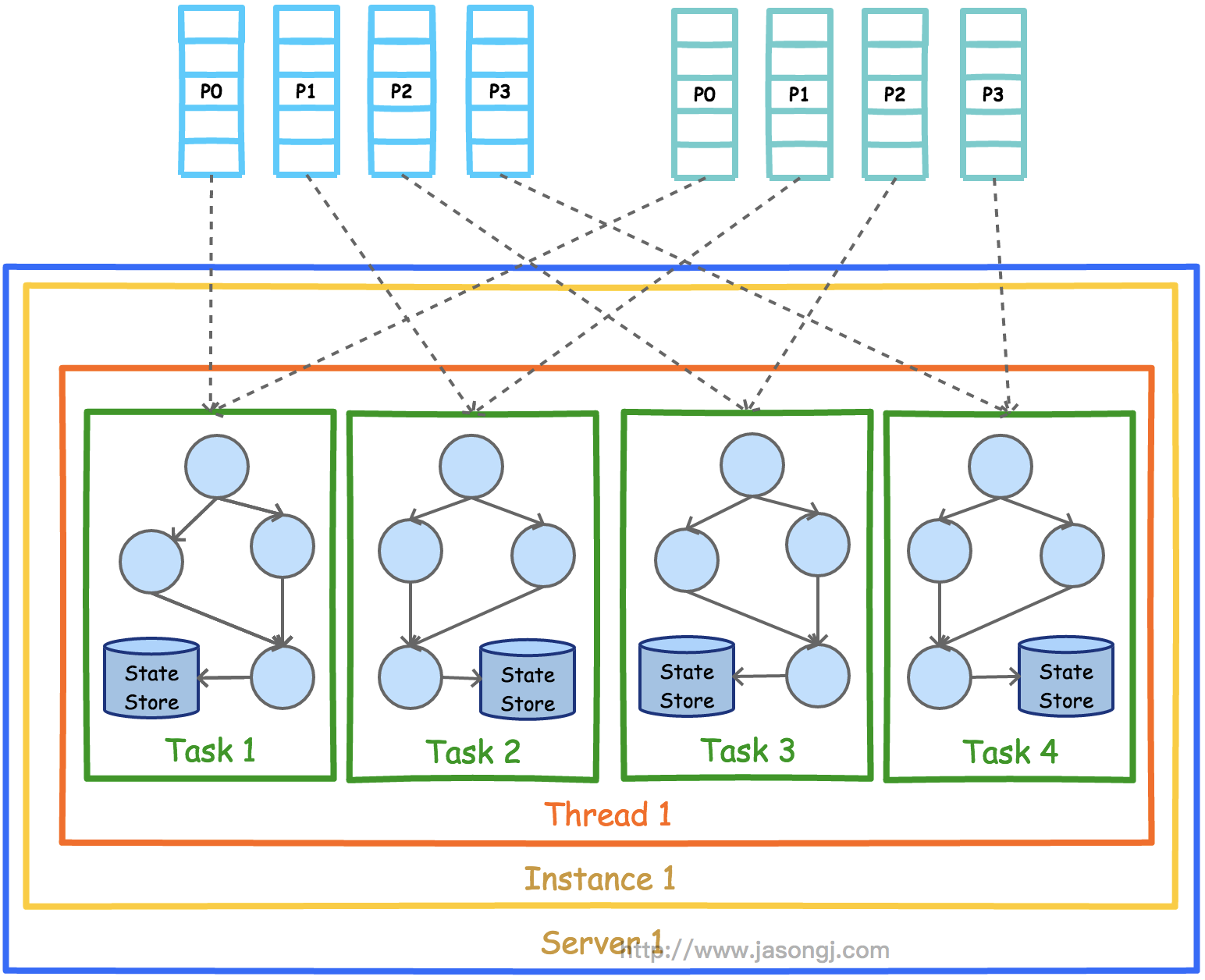
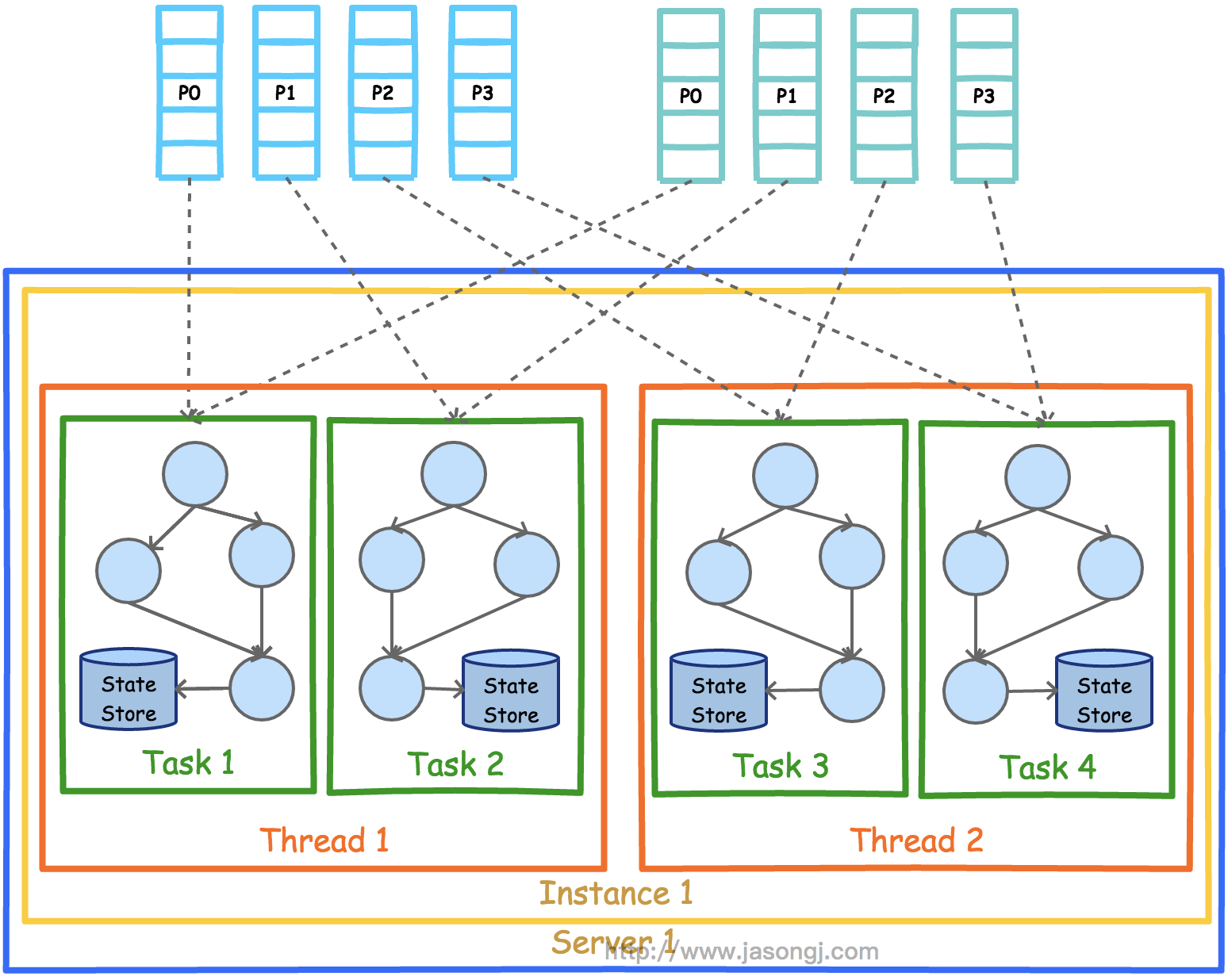
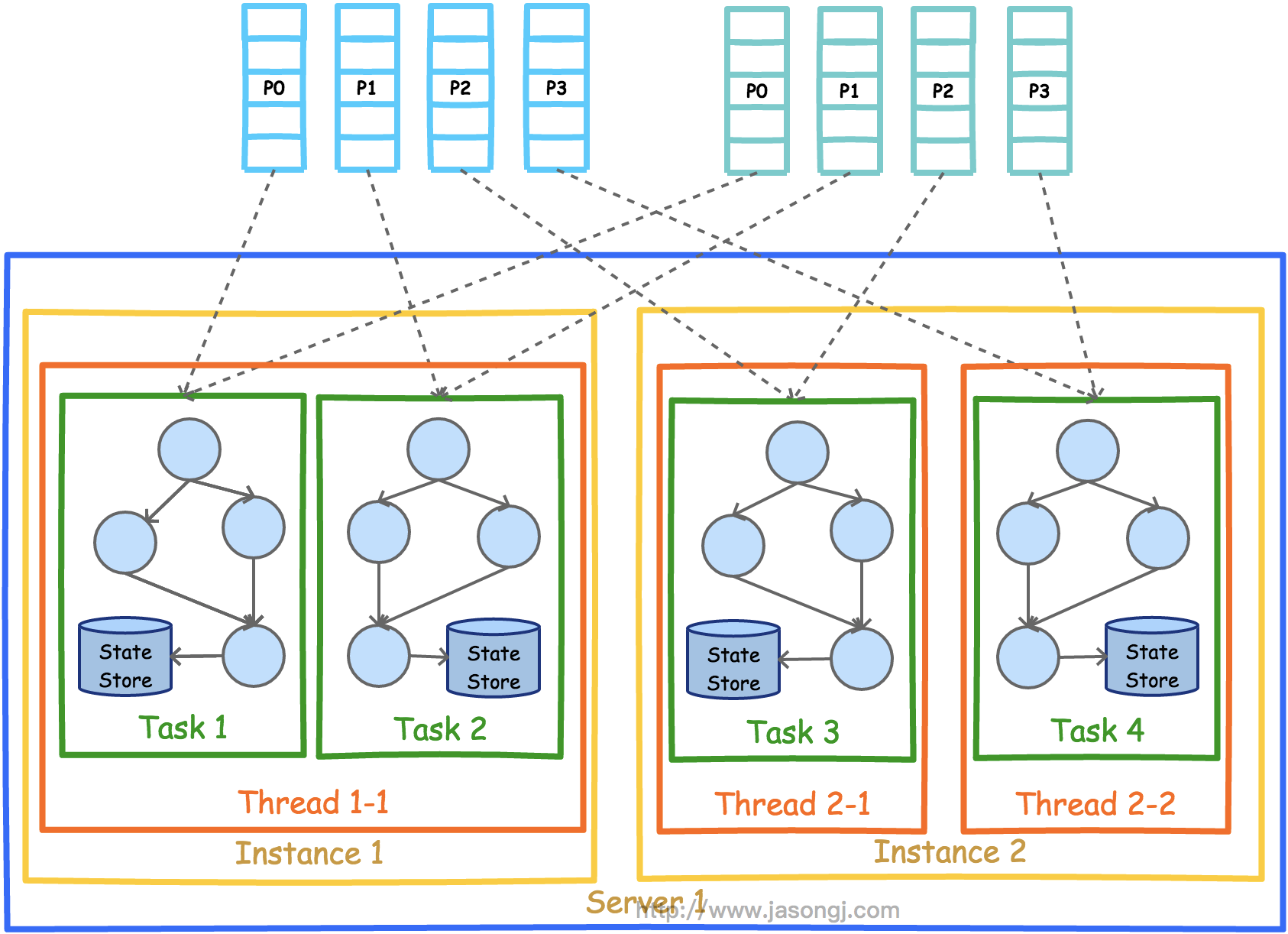
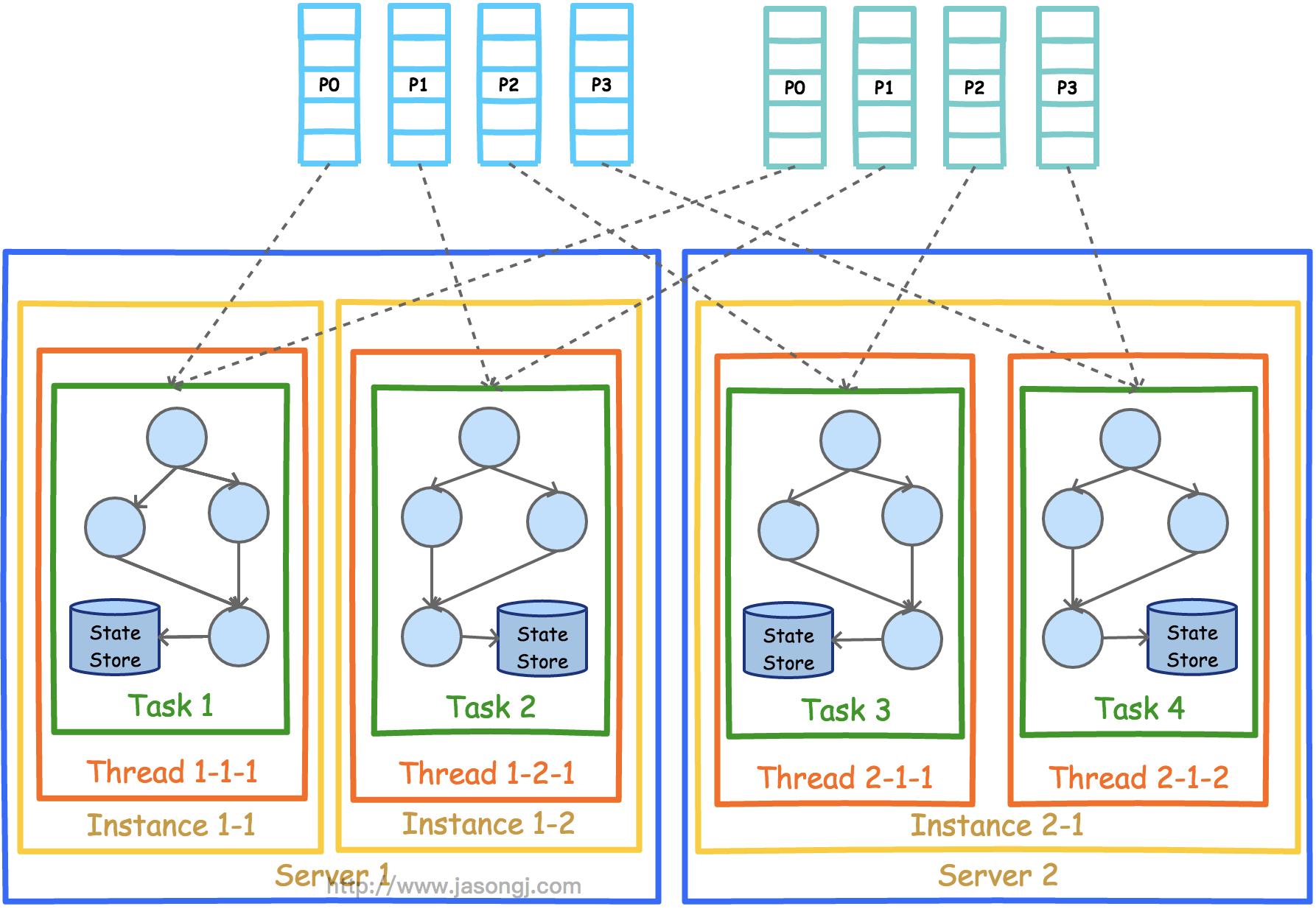
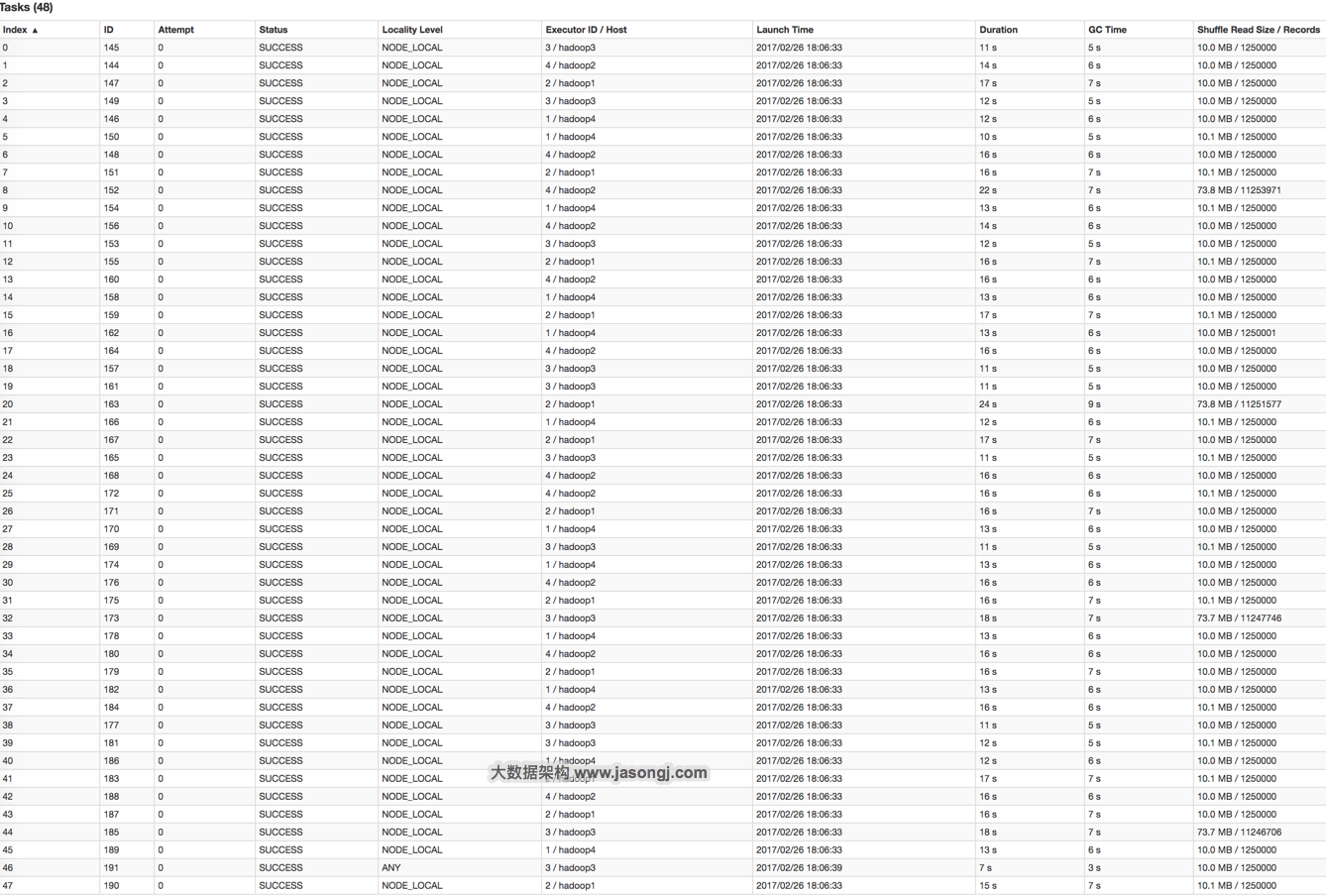
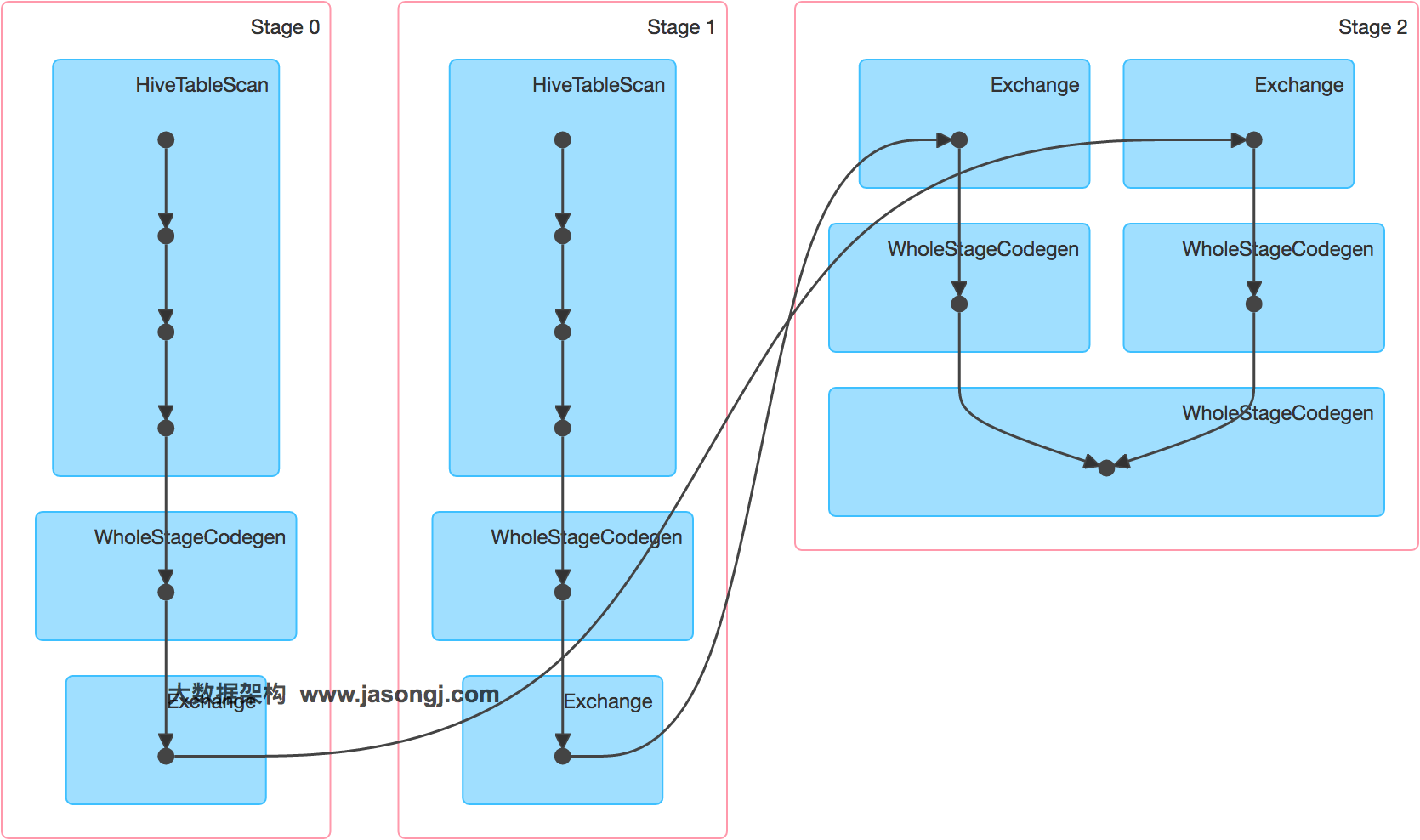
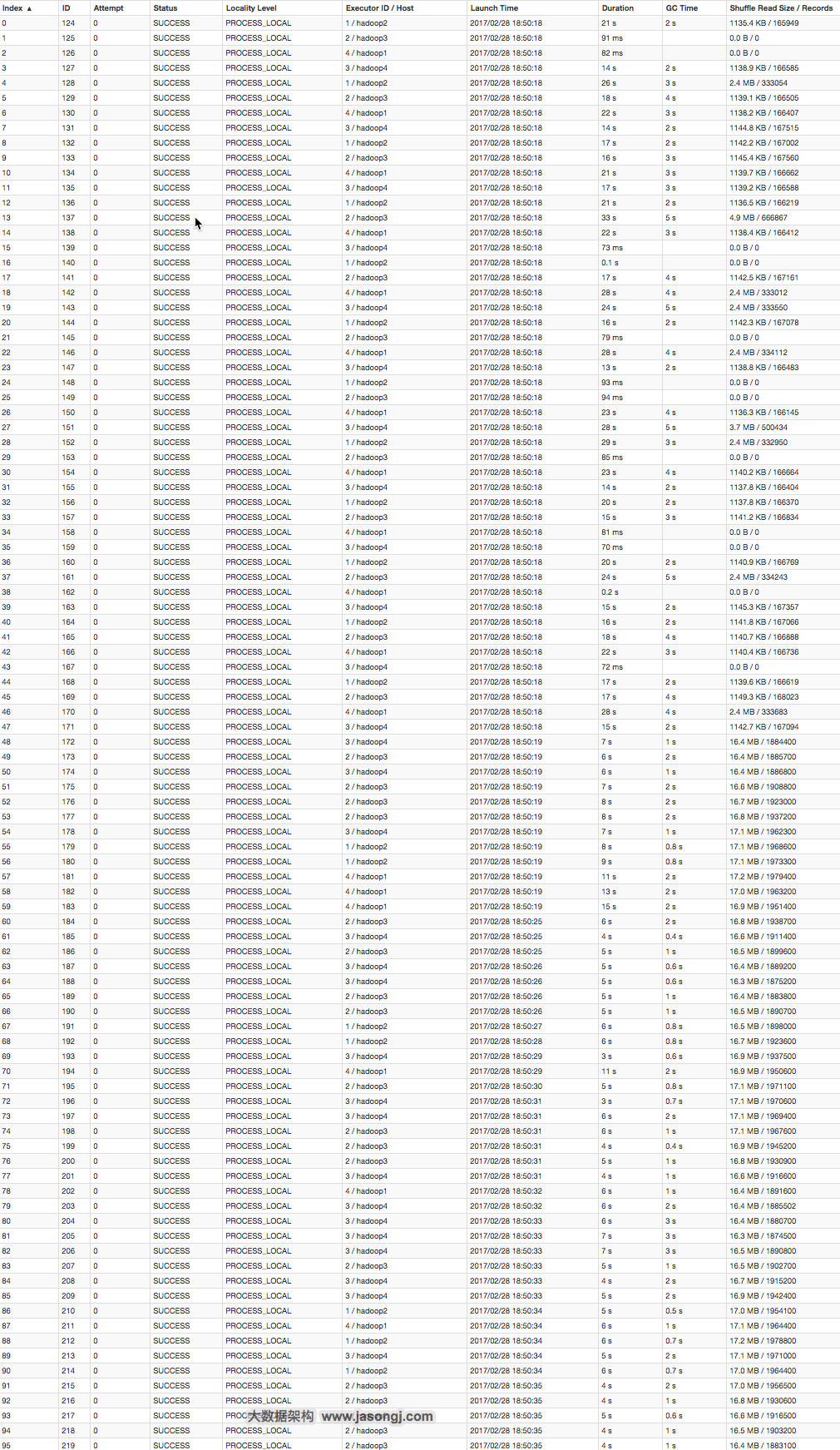
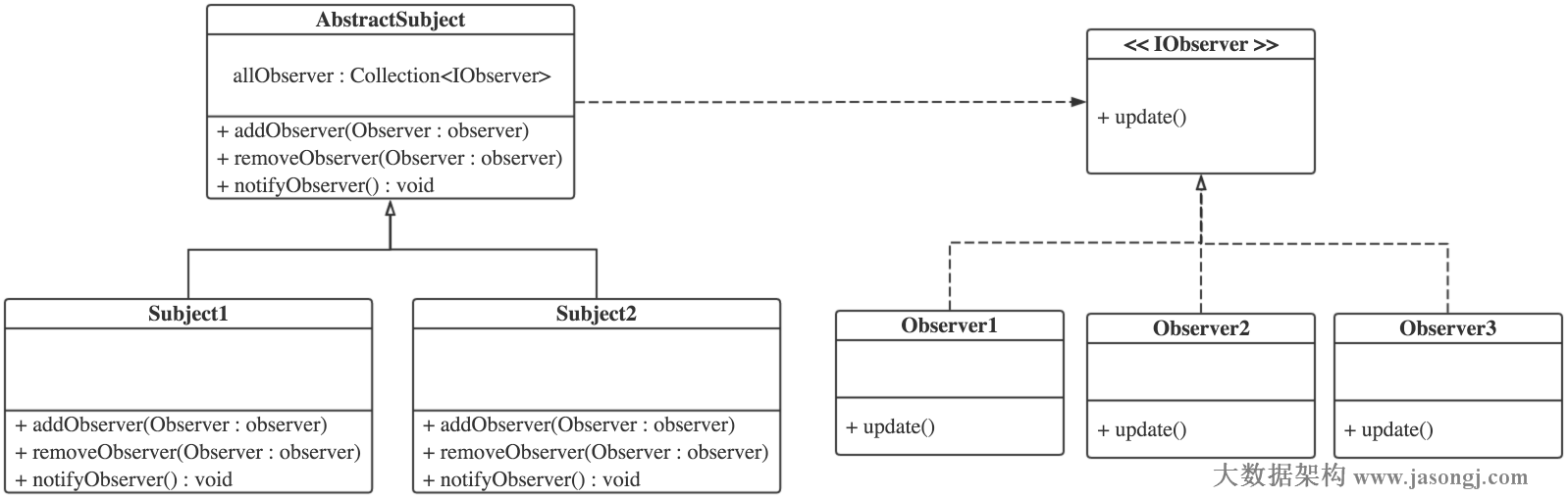
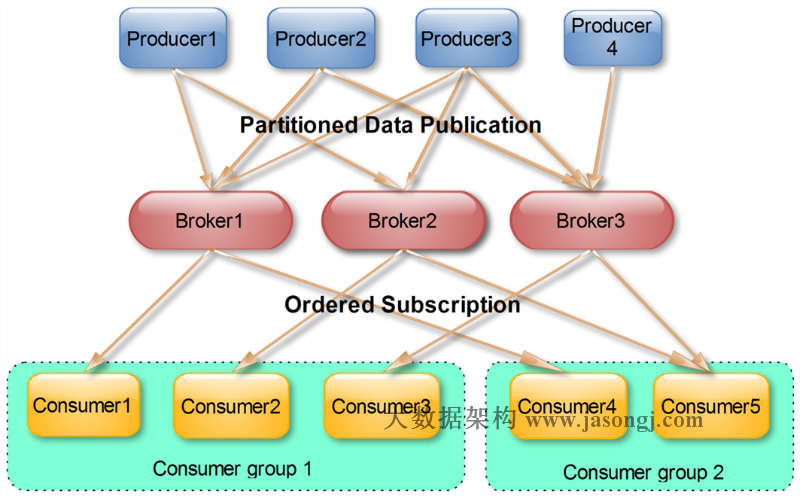
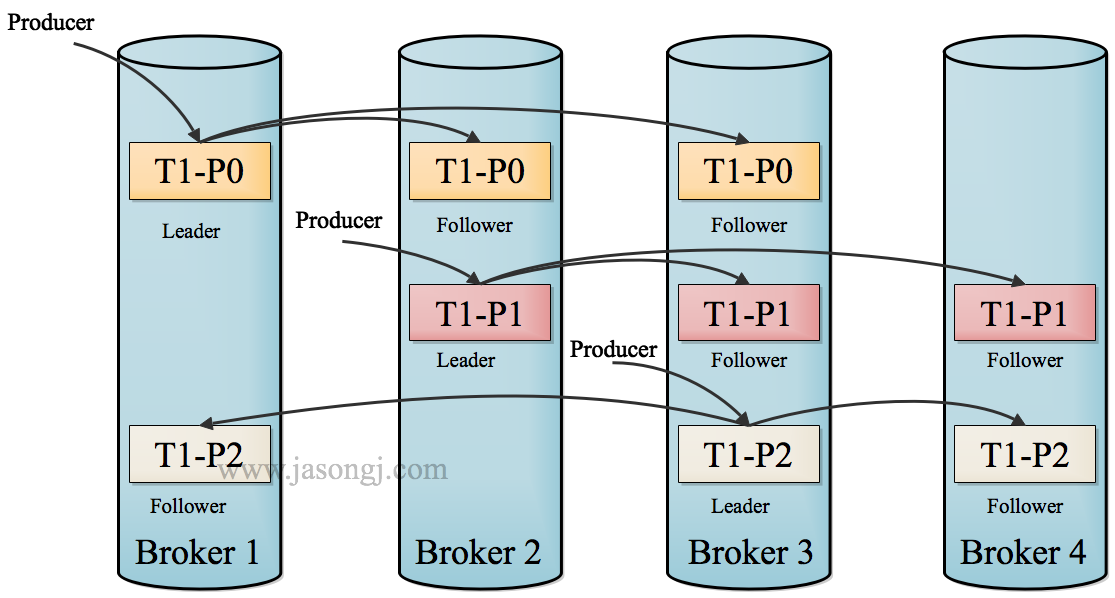
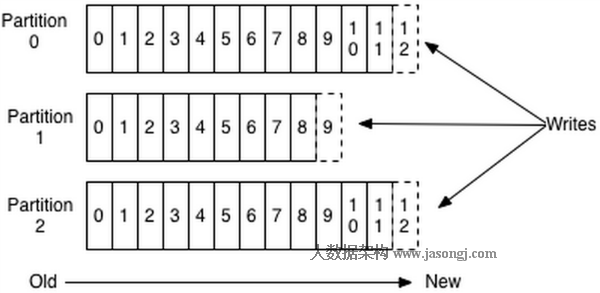
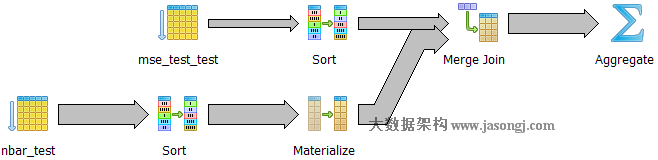
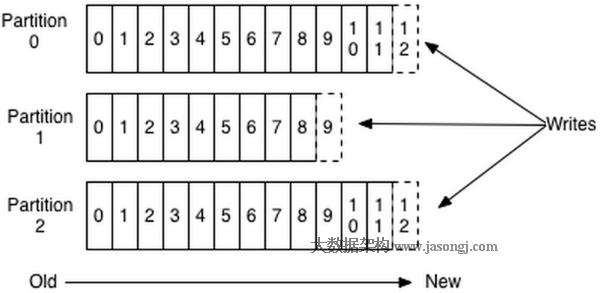
Spark Shuffle 一般用于将上游 Stage 中的数据按 Key 分区,保证来自不同 Mapper (表示上游 Stage 的 Task)的相同的 Key 进入相同的 Reducer (表示下游 Stage 的 Task)。一般用于 group by 或者 Join 操作。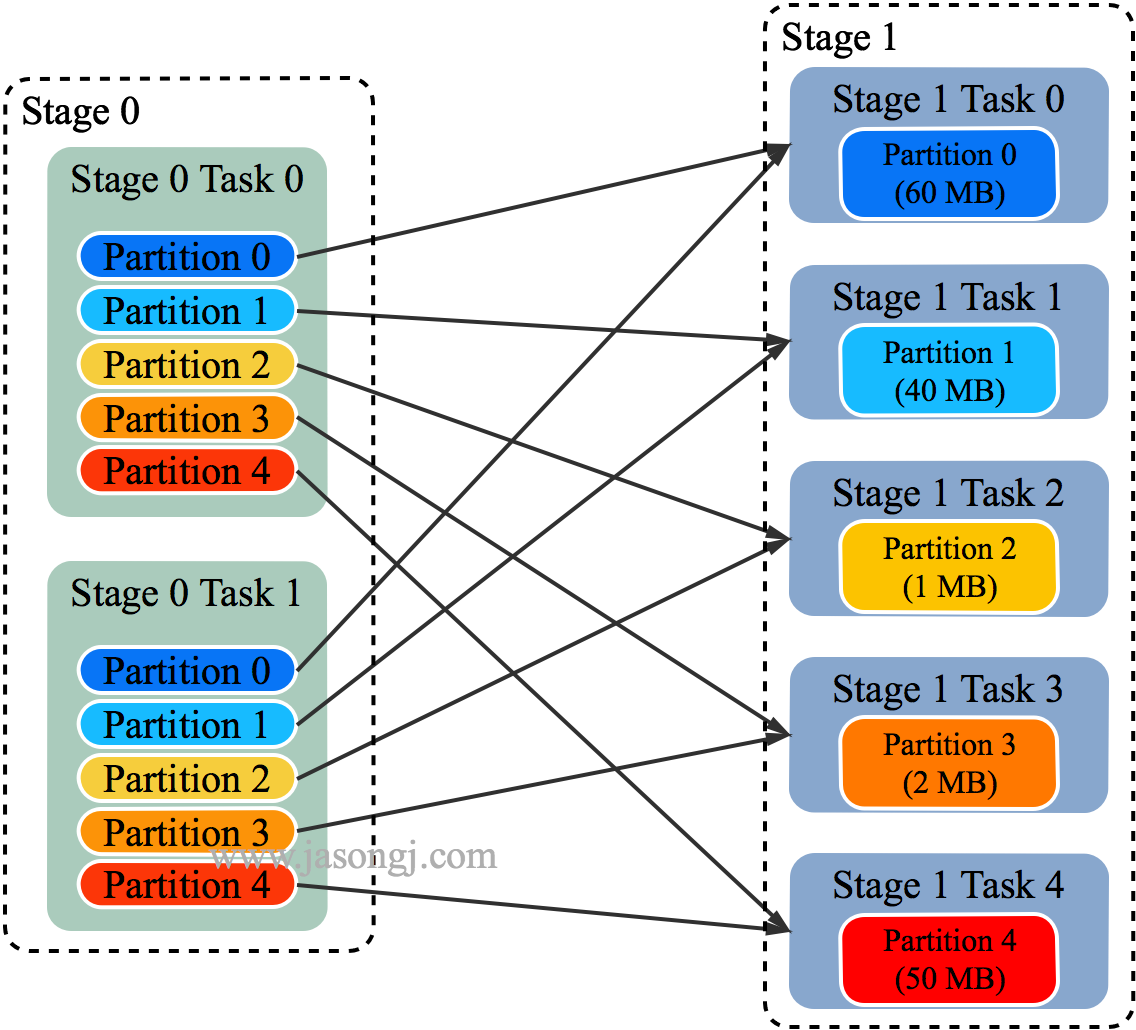
如上图所示,该 Shuffle 总共有 2 个 Mapper 与 5 个 Reducer。每个 Mapper 会按相同的规则(由 Partitioner 定义)将自己的数据分为五份。每个 Reducer 从这两个 Mapper 中拉取属于自己的那一份数据。
2.2 原有 Shuffle 的问题
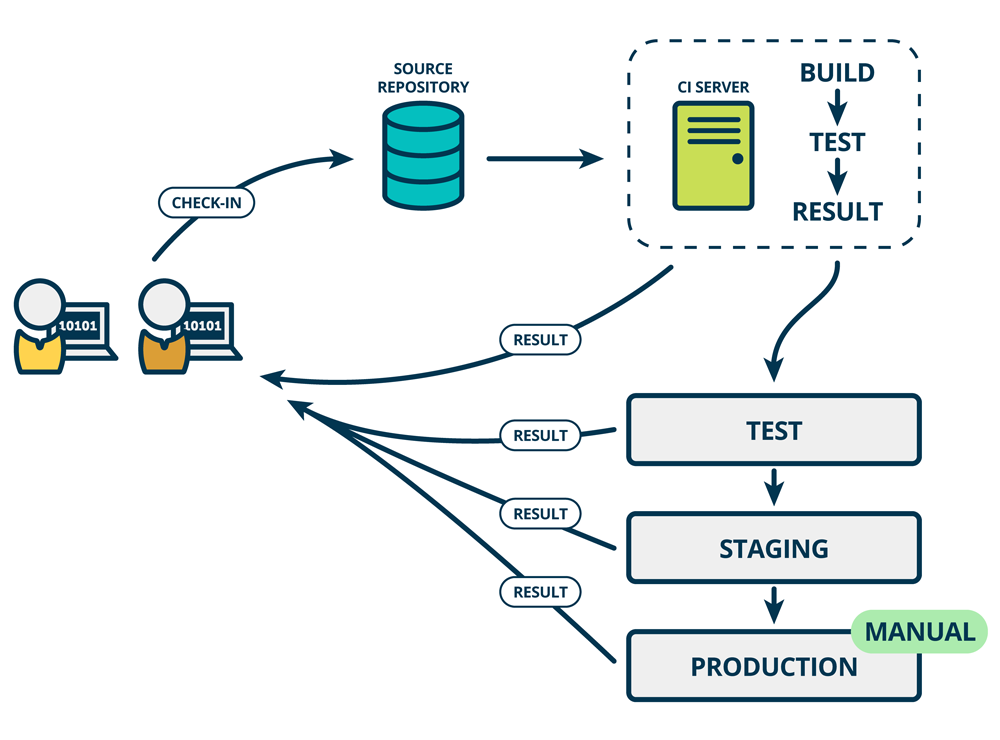
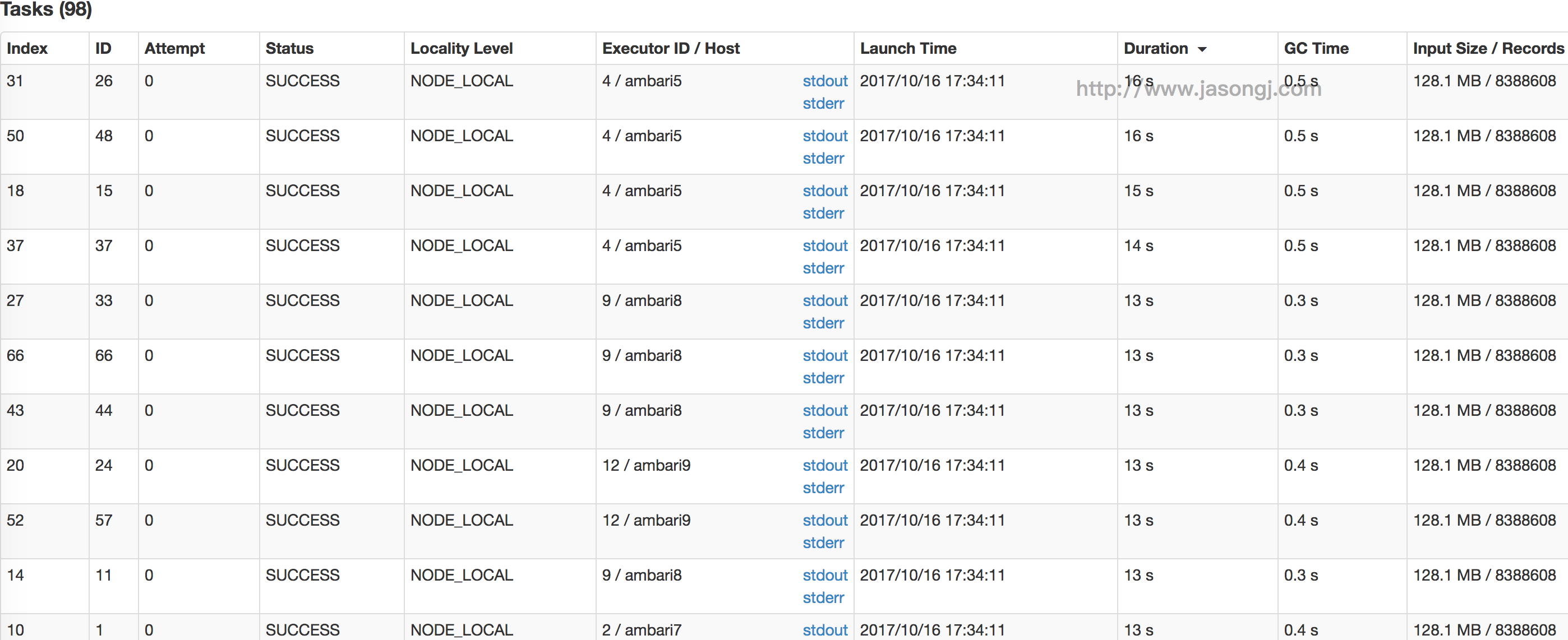
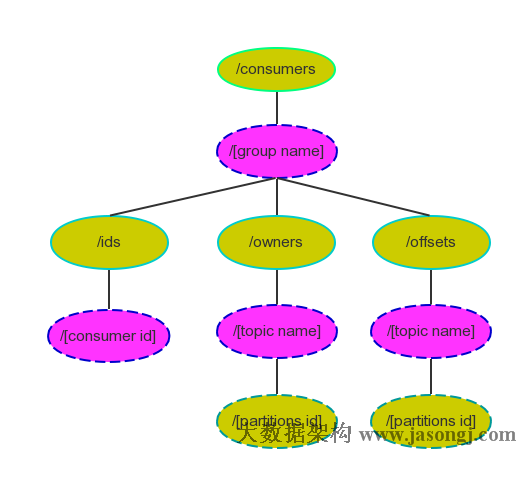
使用 Spark SQL 时,可通过 spark.sql.shuffle.partitions 指定 Shuffle 时 Partition 个数,也即 Reducer 个数
该参数决定了一个 Spark SQL Job 中包含的所有 Shuffle 的 Partition 个数。如下图所示,当该参数值为 3 时,所有 Shuffle 中 Reducer 个数都为 3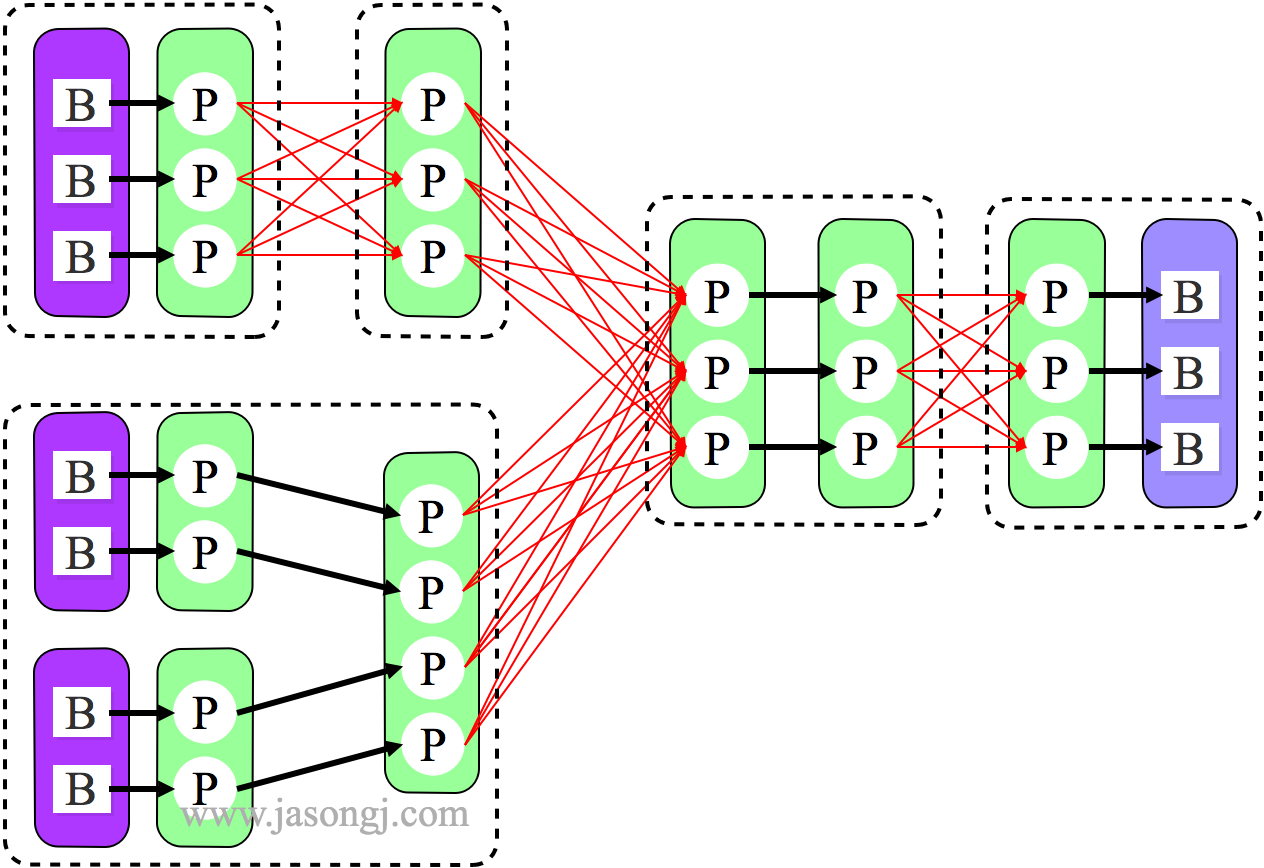
这种方法有如下问题
- Partition 个数不宜设置过大
- Reducer(代指 Spark Shuffle 过程中执行 Shuffle Read 的 Task) 个数过多,每个 Reducer 处理的数据量过小。大量小 Task 造成不必要的 Task 调度开销与可能的资源调度开销(如果开启了 Dynamic Allocation)
- Reducer 个数过大,如果 Reducer 直接写 HDFS 会生成大量小文件,从而造成大量 addBlock RPC,Name node 可能成为瓶颈,并影响其它使用 HDFS 的应用
- 过多 Reducer 写小文件,会造成后面读取这些小文件时产生大量 getBlock RPC,对 Name node 产生冲击
- Partition 个数不宜设置过小
- 每个 Reducer 处理的数据量太大,Spill 到磁盘开销增大
- Reducer GC 时间增长
- Reducer 如果写 HDFS,每个 Reducer 写入数据量较大,无法充分发挥并行处理优势
- 很难保证所有 Shuffle 都最优
- 不同的 Shuffle 对应的数据量不一样,因此最优的 Partition 个数也不一样。使用统一的 Partition 个数很难保证所有 Shuffle 都最优
- 定时任务不同时段数据量不一样,相同的 Partition 数设置无法保证所有时间段执行时都最优
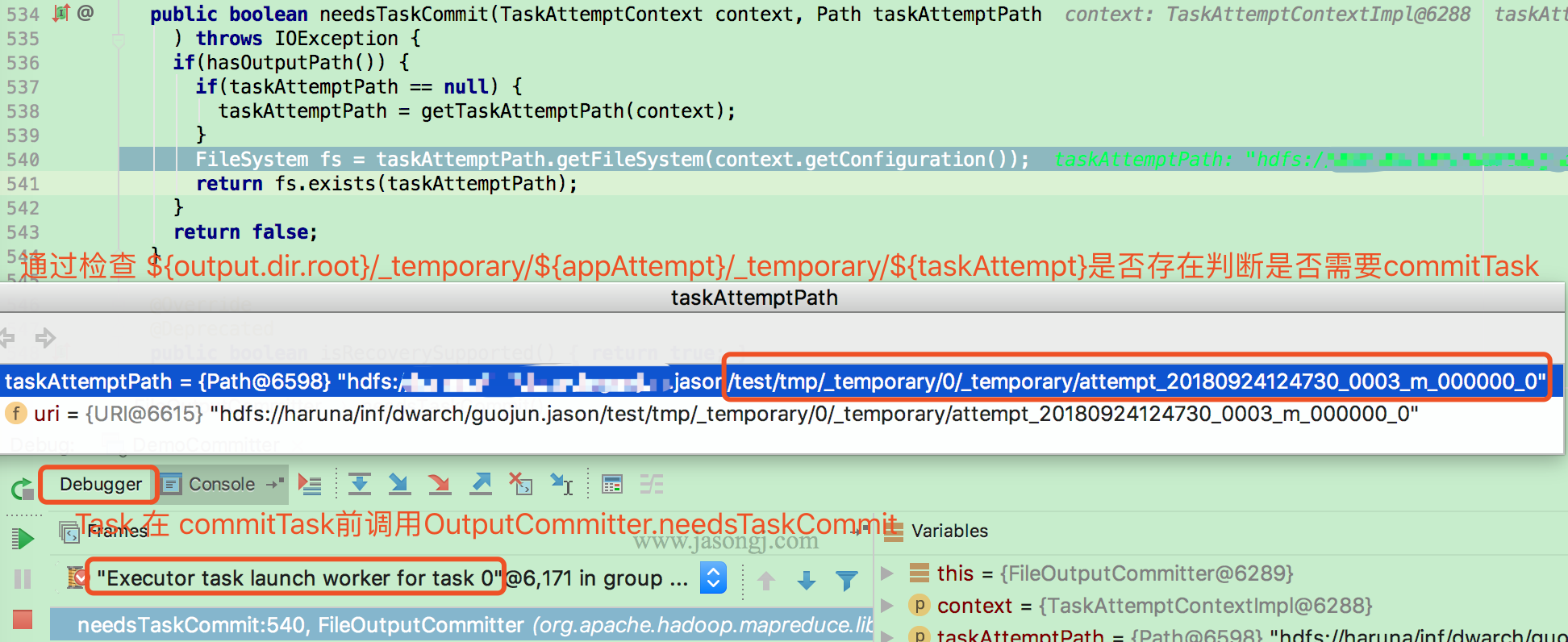
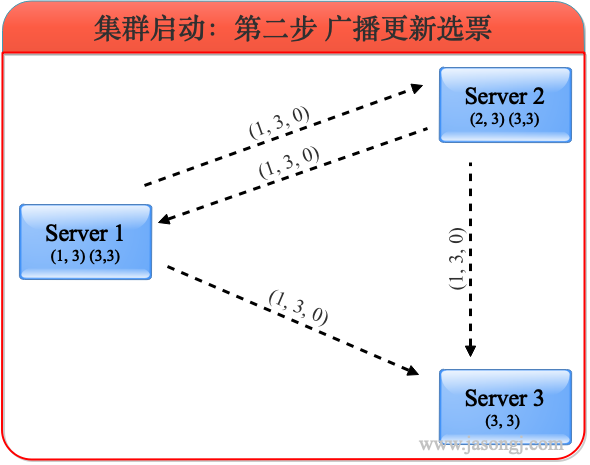
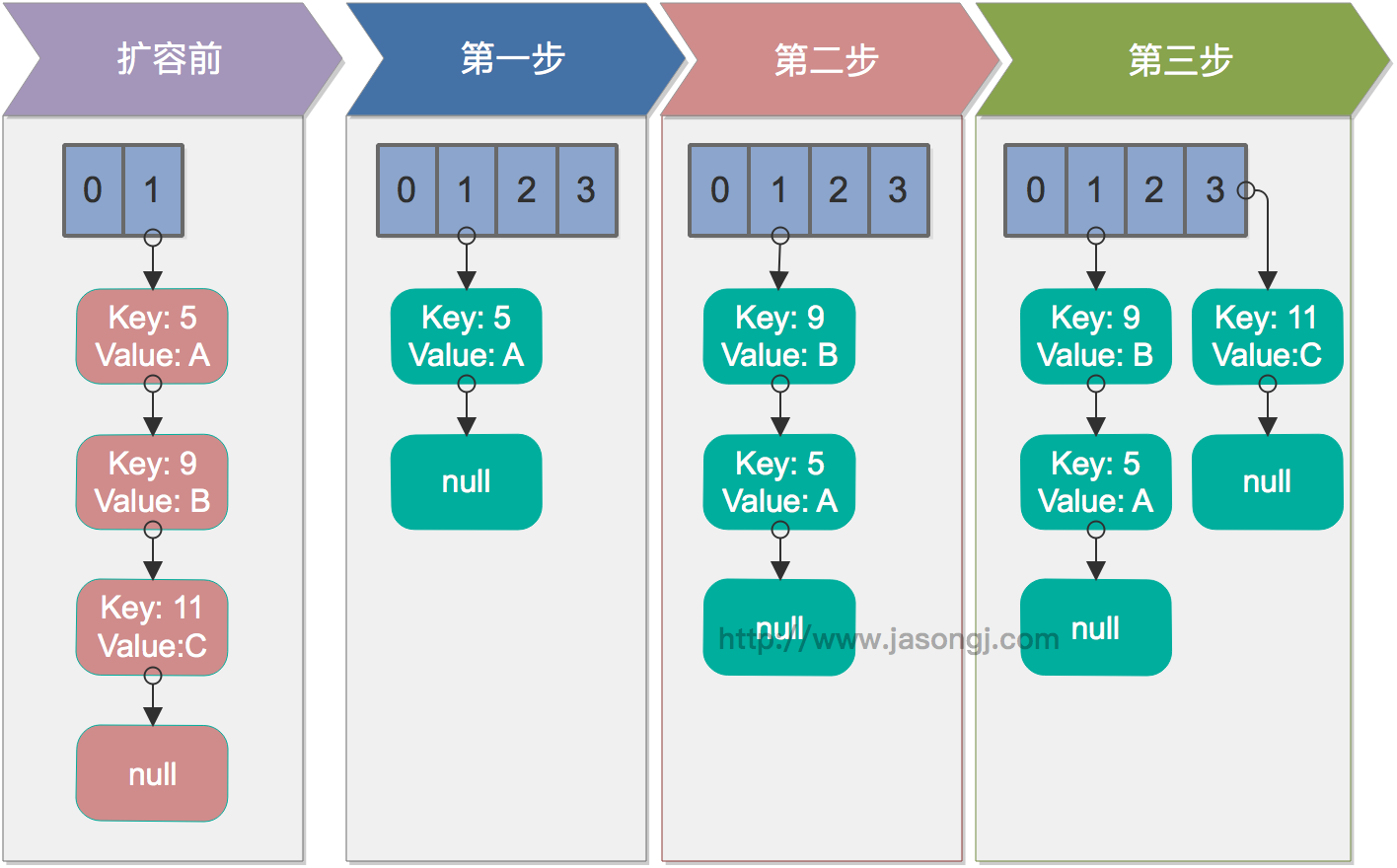
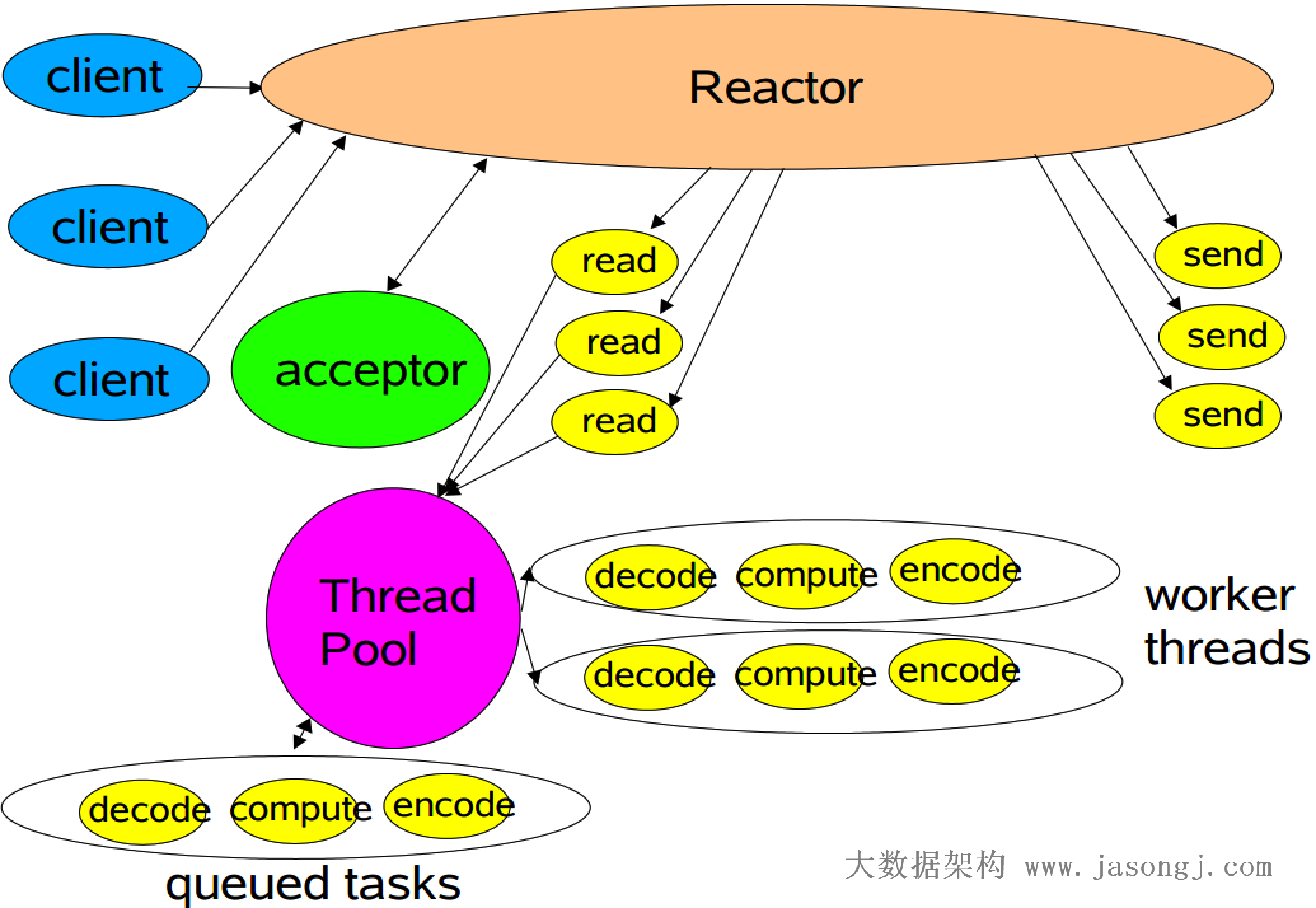
2.3 自动设置 Shuffle Partition 原理
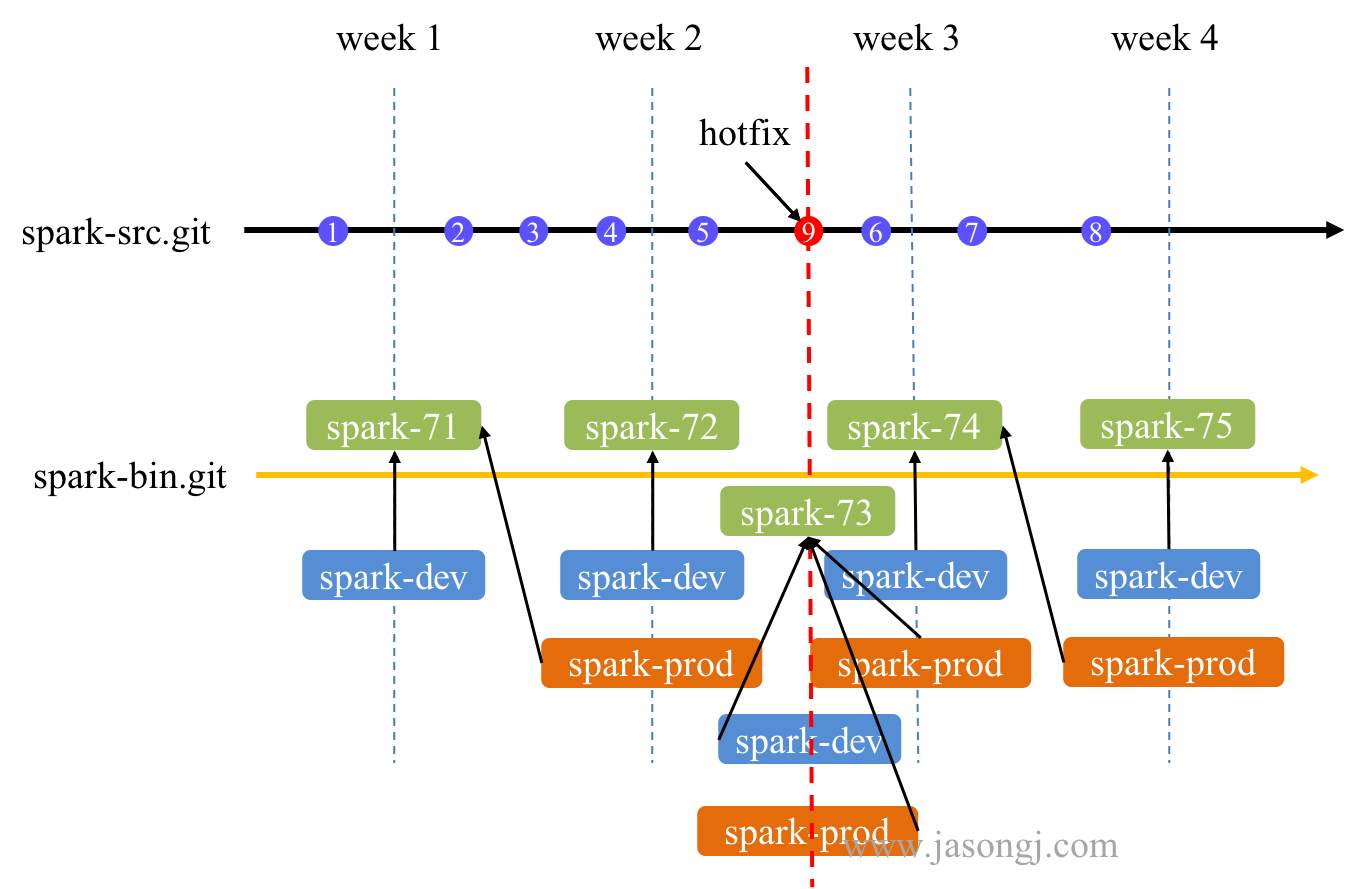
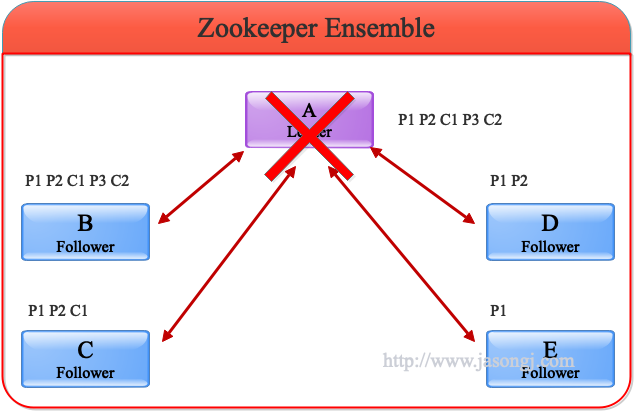
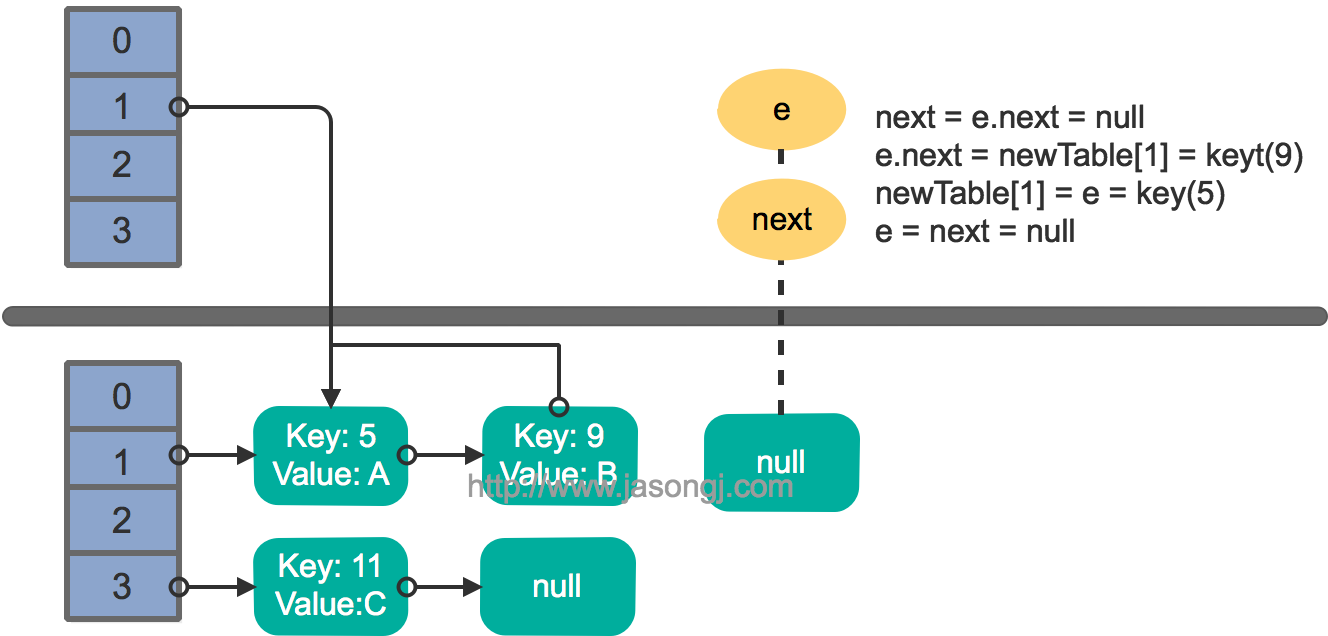
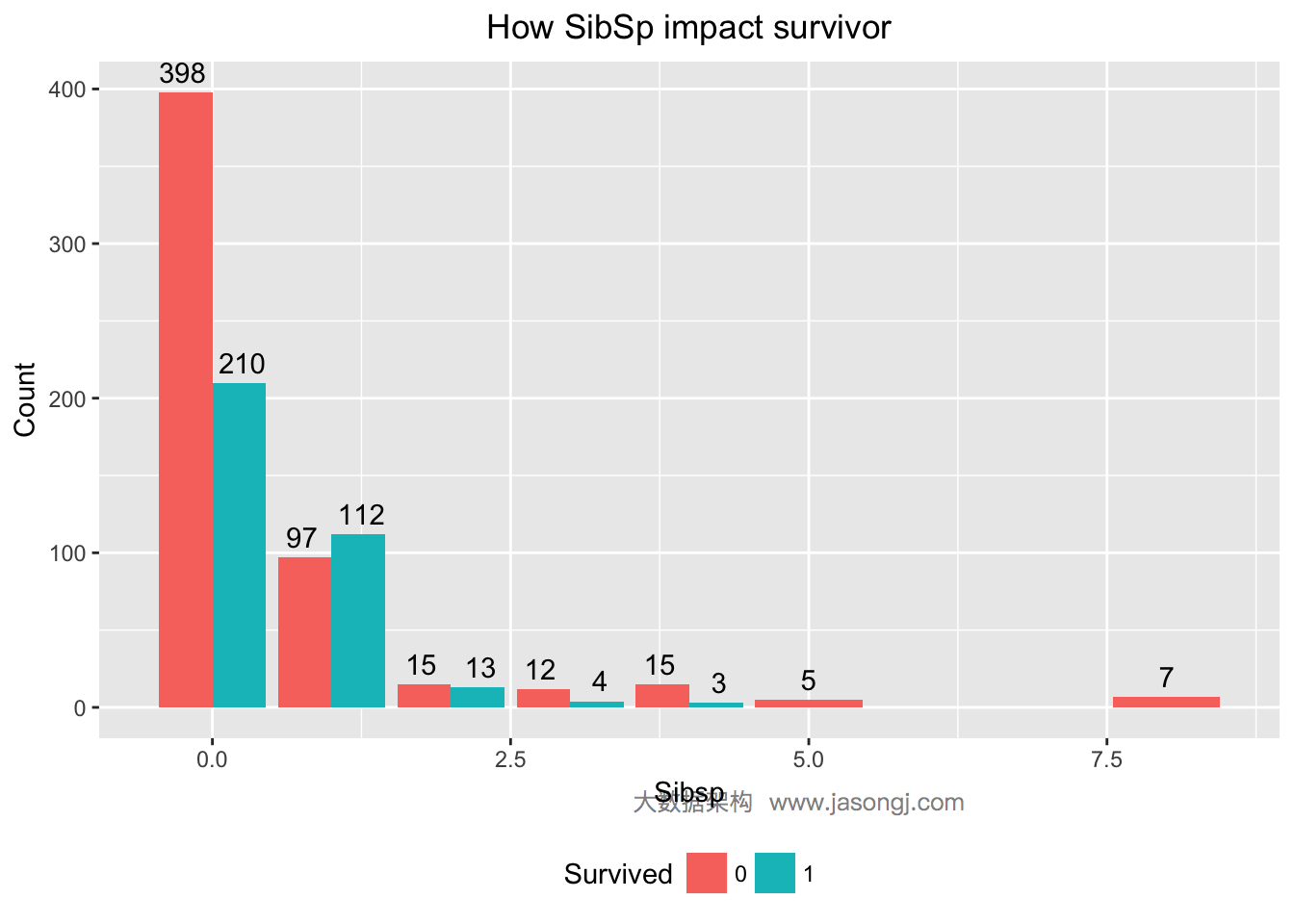
如 Spark Shuffle 原理 一节图中所示,Stage 1 的 5 个 Partition 数据量分别为 60MB,40MB,1MB,2MB,50MB。其中 1MB 与 2MB 的 Partition 明显过小(实际场景中,部分小 Partition 只有几十 KB 及至几十字节)
开启 Adaptive Execution 后
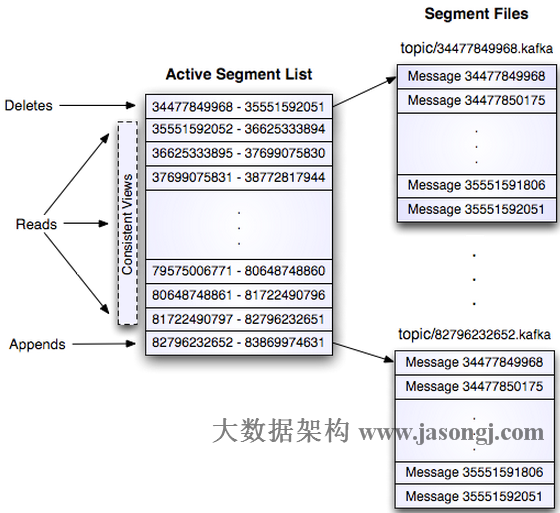
- Spark 在 Stage 0 的 Shuffle Write 结束后,根据各 Mapper 输出,统计得到各 Partition 的数据量,即 60MB,40MB,1MB,2MB,50MB
- 通过 ExchangeCoordinator 计算出合适的 post-shuffle Partition 个数(即 Reducer)个数(本例中 Reducer 个数设置为 3)
- 启动相应个数的 Reducer 任务
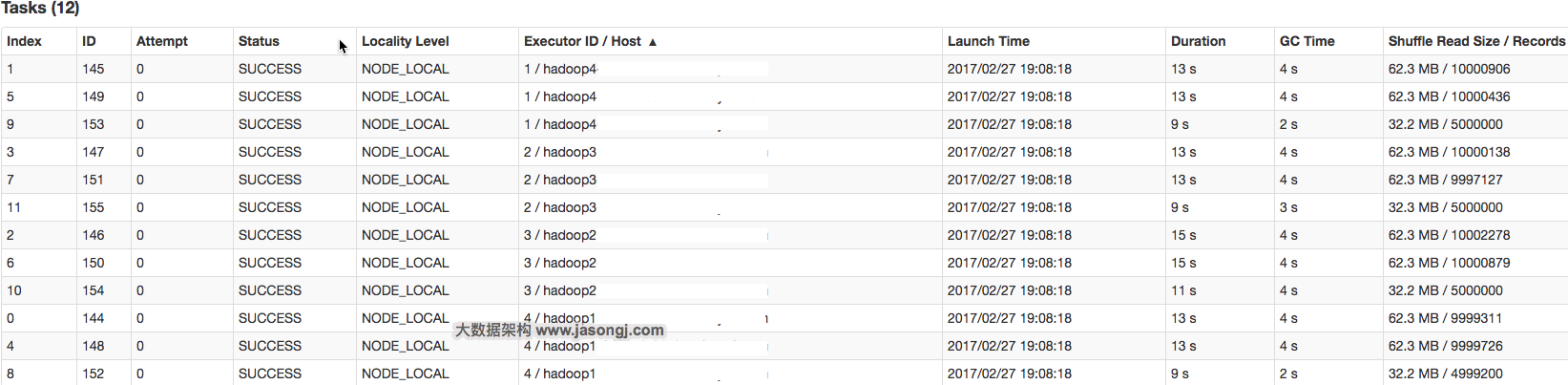
- 每个 Reducer 读取一个或多个 Shuffle Write Partition 数据(如下图所示,Reducer 0 读取 Partition 0,Reducer 1 读取 Partition 1、2、3,Reducer 2 读取 Partition 4)
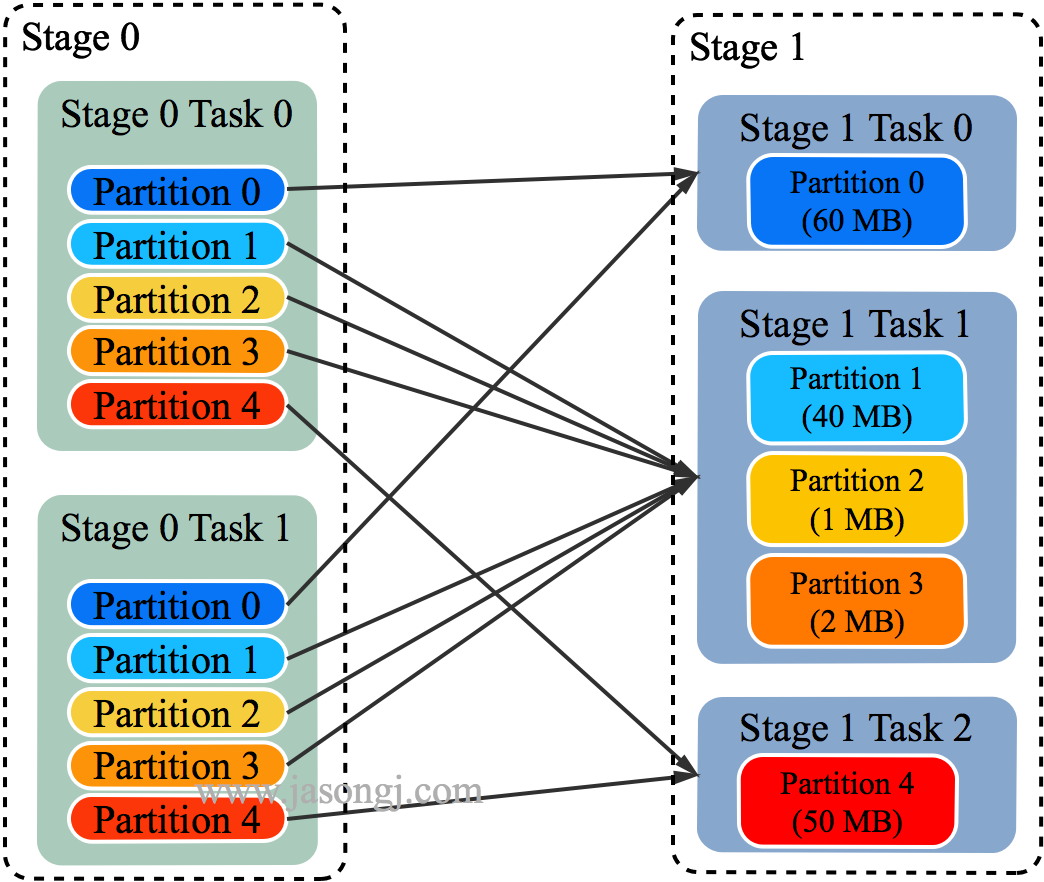
三个 Reducer 这样分配是因为
- targetPostShuffleInputSize 默认为 64MB,每个 Reducer 读取数据量不超过 64MB
- 如果 Partition 0 与 Partition 2 结合,Partition 1 与 Partition 3 结合,虽然也都不超过 64 MB。但读完 Partition 0 再读 Partition 2,对于同一个 Mapper 而言,如果每个 Partition 数据比较少,跳着读多个 Partition 相当于随机读,在 HDD 上性能不高
- 目前的做法是只结合相临的 Partition,从而保证顺序读,提高磁盘 IO 性能
- 该方案只会合并多个小的 Partition,不会将大的 Partition 拆分,因为拆分过程需要引入一轮新的 Shuffle
- 基于上面的原因,默认 Partition 个数(本例中为 5)可以大一点,然后由 ExchangeCoordinator 合并。如果设置的 Partition 个数太小,Adaptive Execution 在此场景下无法发挥作用
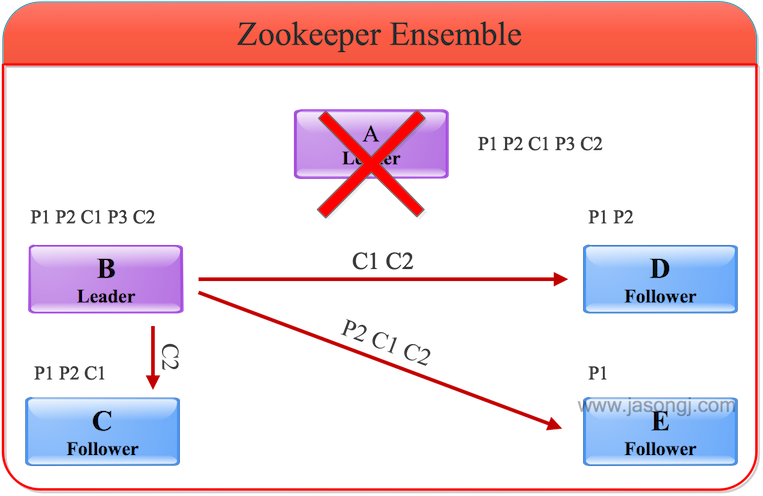
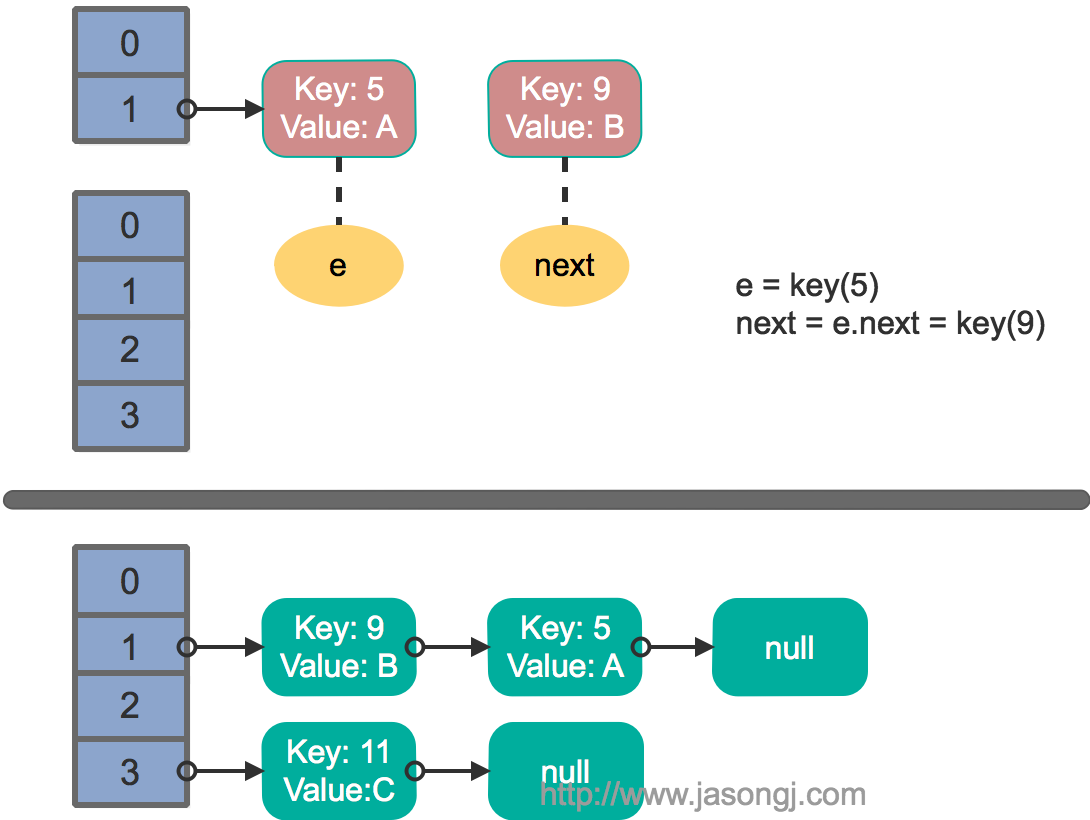
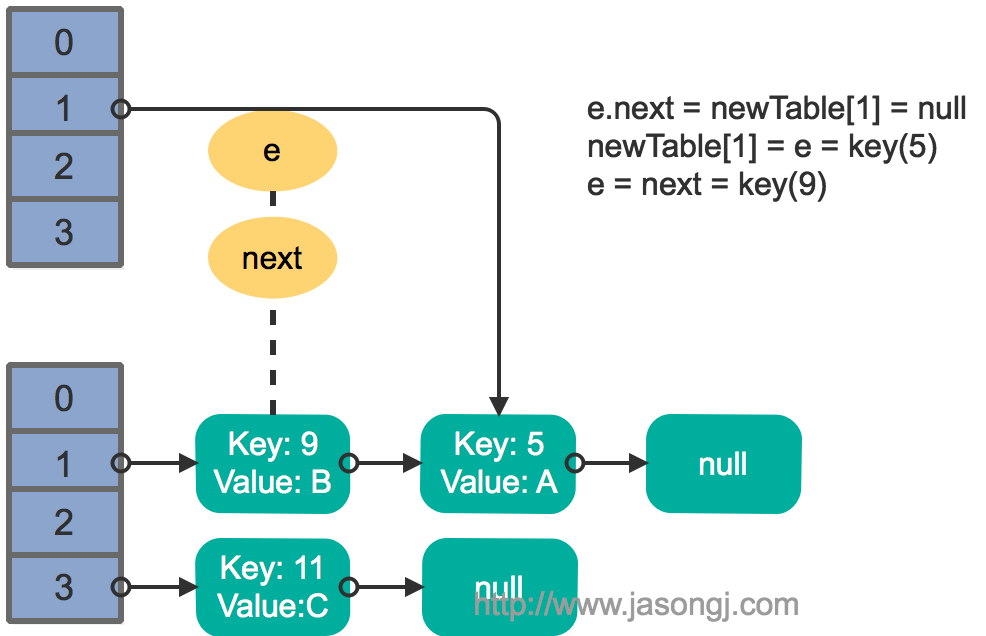
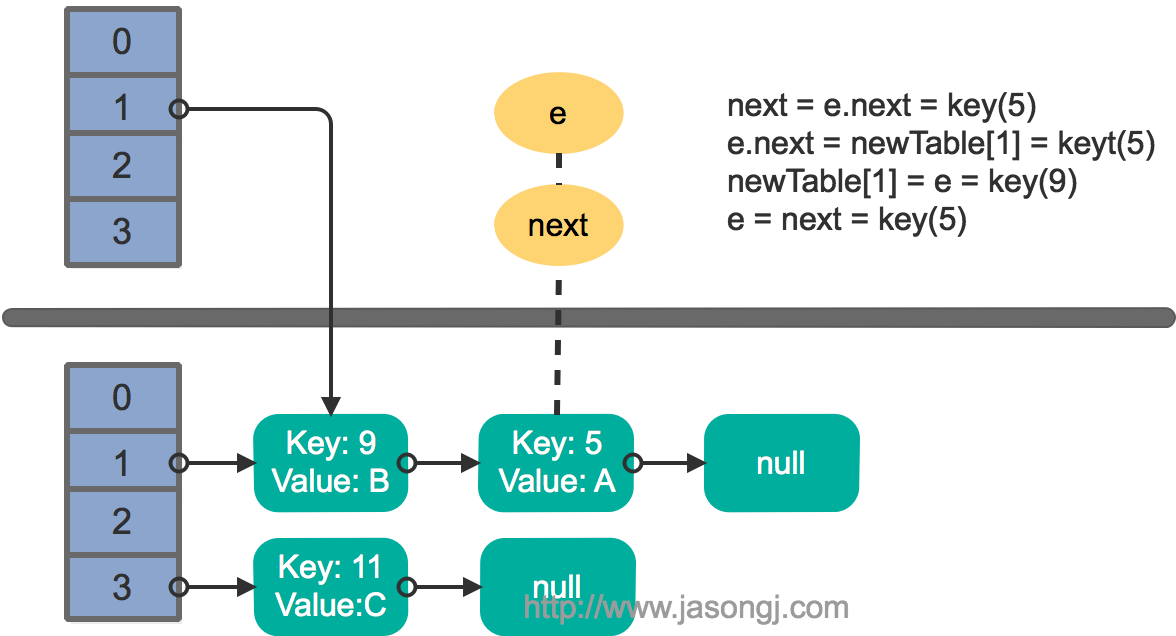
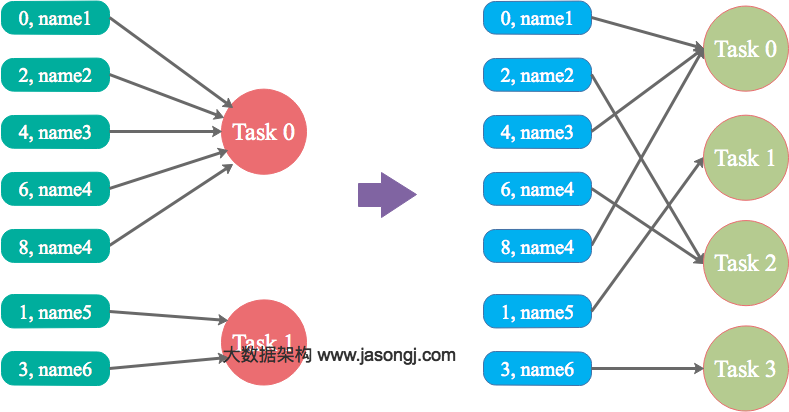
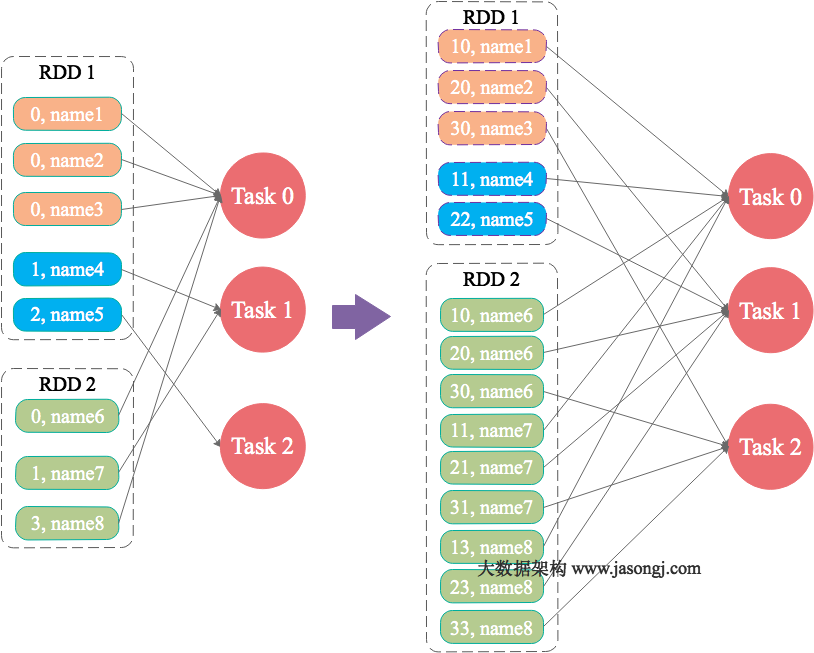
由上图可见,Reducer 1 从每个 Mapper 读取 Partition 1、2、3 都有三根线,是因为原来的 Shuffle 设计中,每个 Reducer 每次通过 Fetch 请求从一个特定 Mapper 读数据时,只能读一个 Partition 的数据。也即在上图中,Reducer 1 读取 Mapper 0 的数据,需要 3 轮 Fetch 请求。对于 Mapper 而言,需要读三次磁盘,相当于随机 IO。
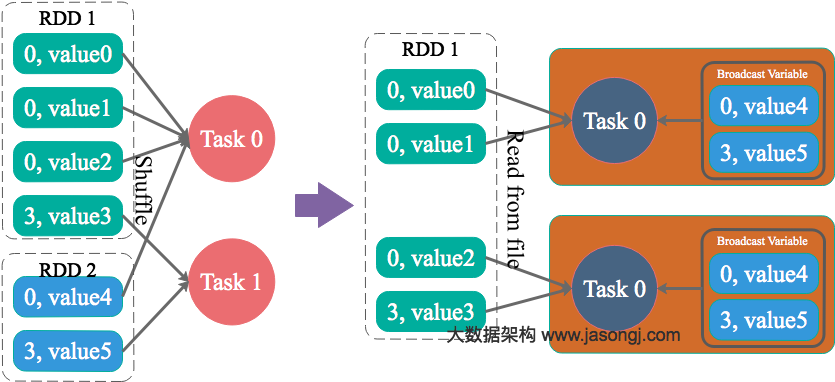
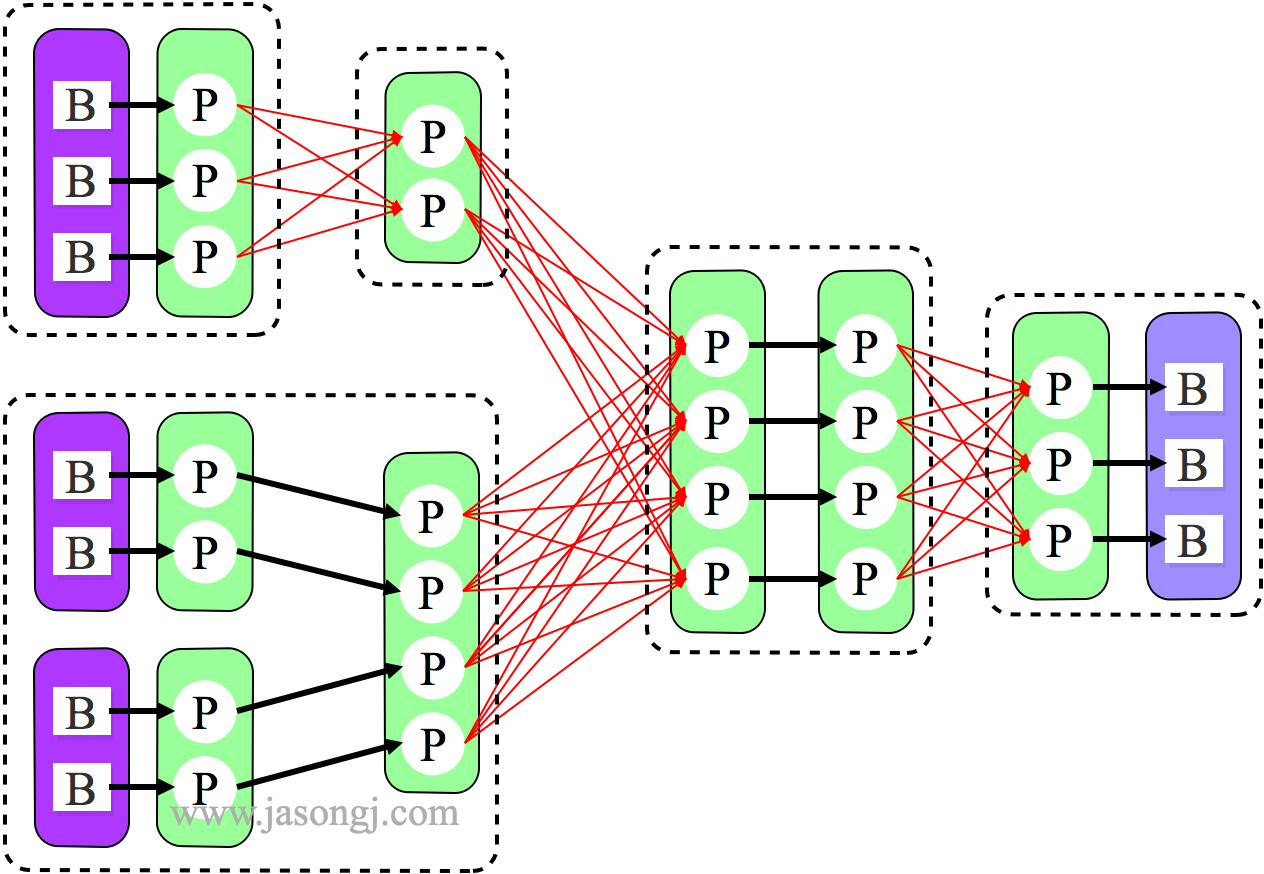
为了解决这个问题,Spark 新增接口,一次 Shuffle Read 可以读多个 Partition 的数据。如下图所示,Task 1 通过一轮请求即可同时读取 Task 0 内 Partition 0、1 和 2 的数据,减少了网络请求数量。同时 Mapper 0 一次性读取并返回三个 Partition 的数据,相当于顺序 IO,从而提升了性能。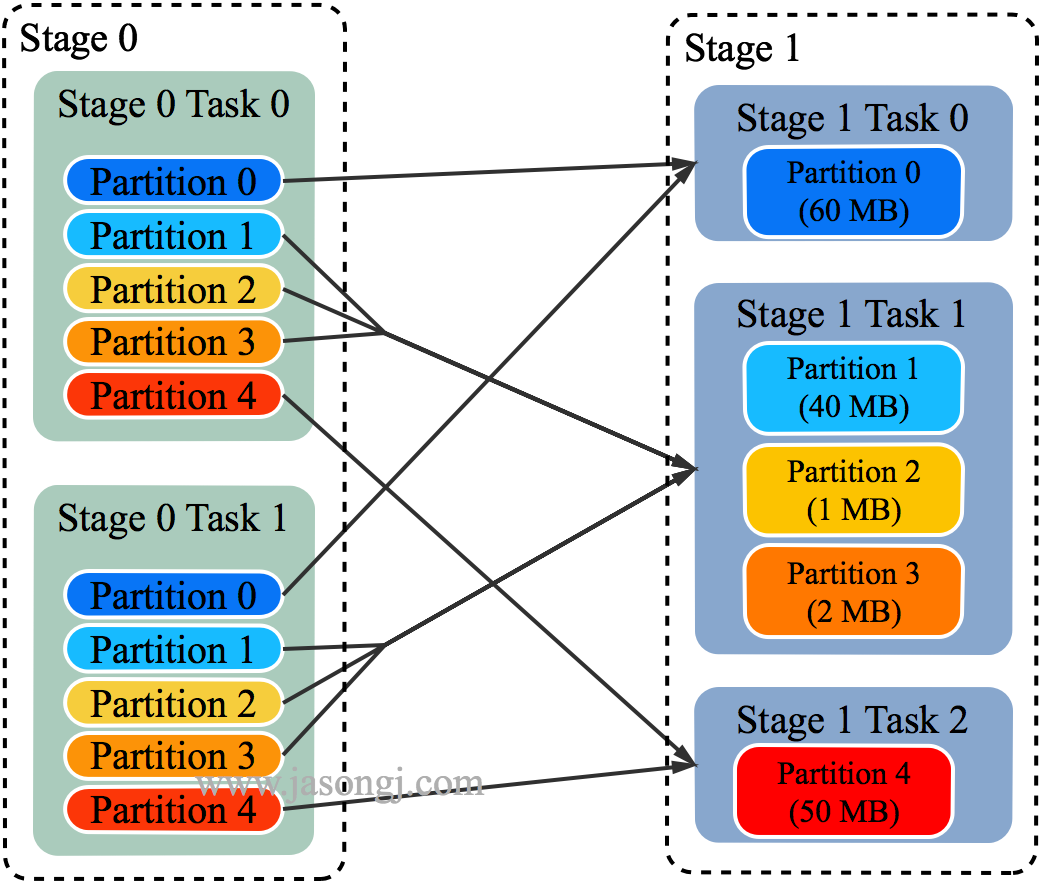
由于 Adaptive Execution 的自动设置 Reducer 是由 ExchangeCoordinator 根据 Shuffle Write 统计信息决定的,因此即使在同一个 Job 中不同 Shuffle 的 Reducer 个数都可以不一样,从而使得每次 Shuffle 都尽可能最优。
上文 原有 Shuffle 的问题 一节中的例子,在启用 Adaptive Execution 后,三次 Shuffle 的 Reducer 个数从原来的全部为 3 变为 2、4、3。
2.4 使用与优化方法
可通过 spark.sql.adaptive.enabled=true 启用 Adaptive Execution 从而启用自动设置 Shuffle Reducer 这一特性
通过 spark.sql.adaptive.shuffle.targetPostShuffleInputSize 可设置每个 Reducer 读取的目标数据量,其单位是字节,默认值为 64 MB。上文例子中,如果将该值设置为 50 MB,最终效果仍然如上文所示,而不会将 Partition 0 的 60MB 拆分。具体原因上文已说明
3 动态调整执行计划
3.1 固定执行计划的不足
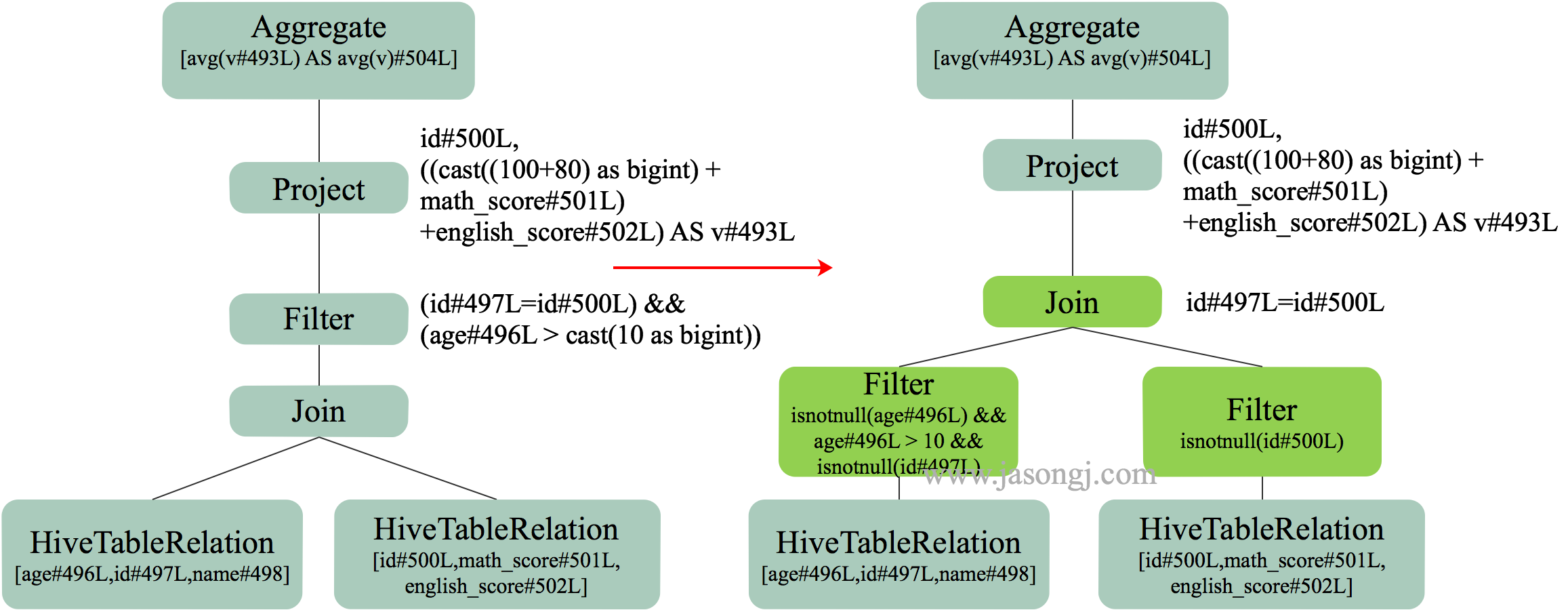
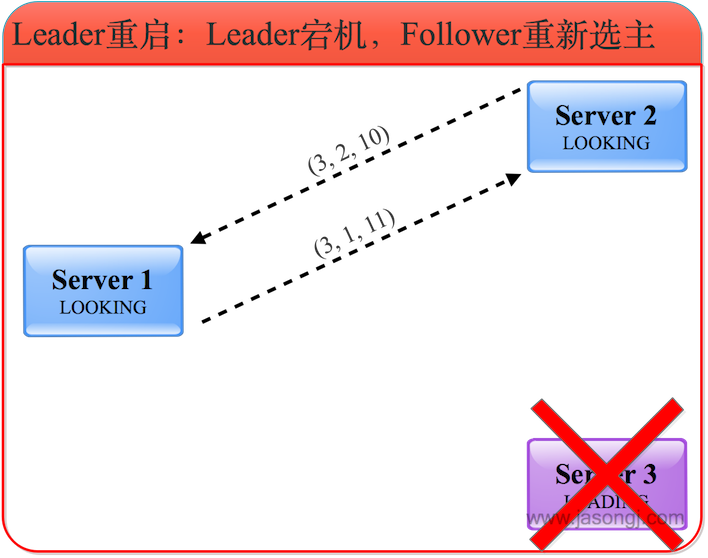
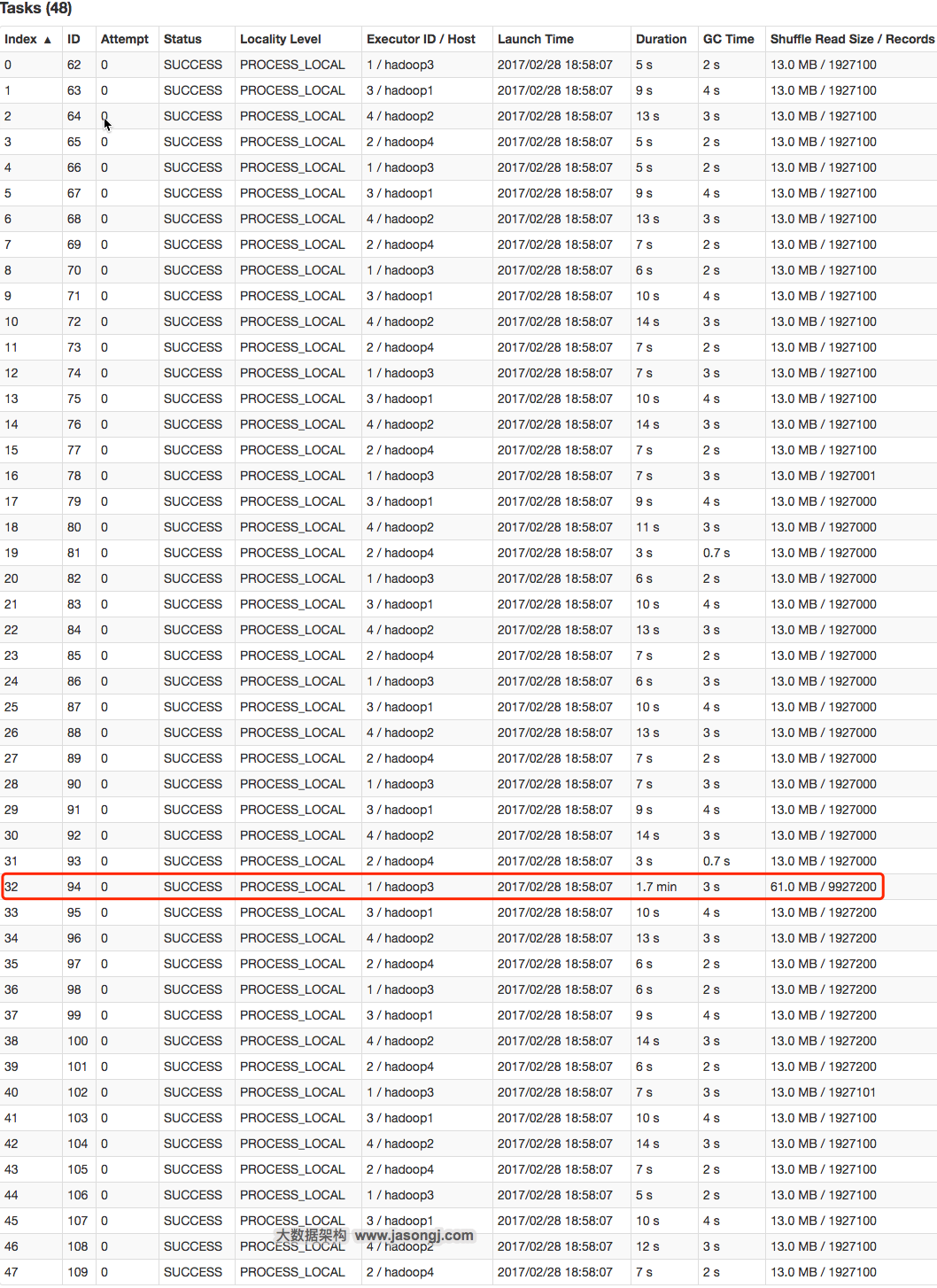
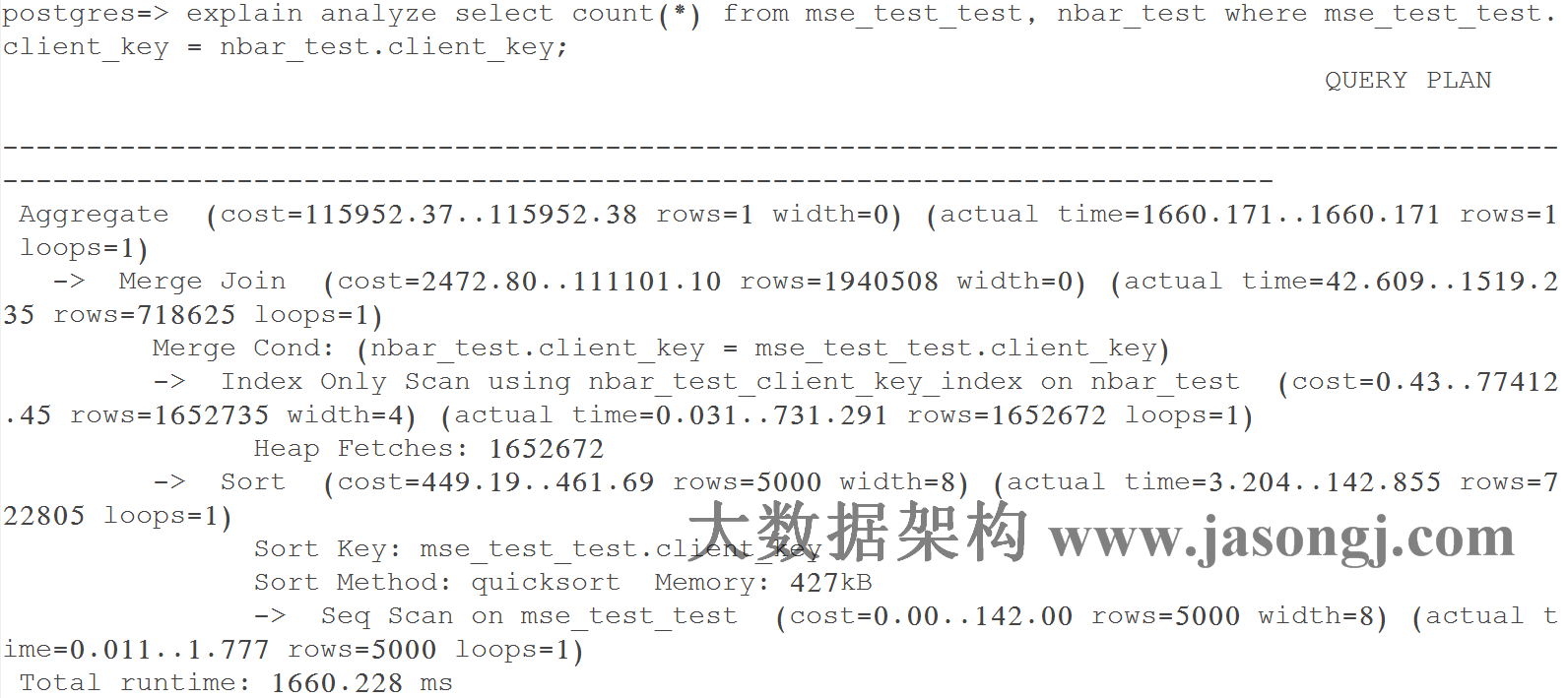
在不开启 Adaptive Execution 之前,执行计划一旦确定,即使发现后续执行计划可以优化,也不可更改。如下图所示,SortMergJoin 的 Shuffle Write 结束后,发现 Join 一方的 Shuffle 输出只有 46.9KB,仍然继续执行 SortMergeJoin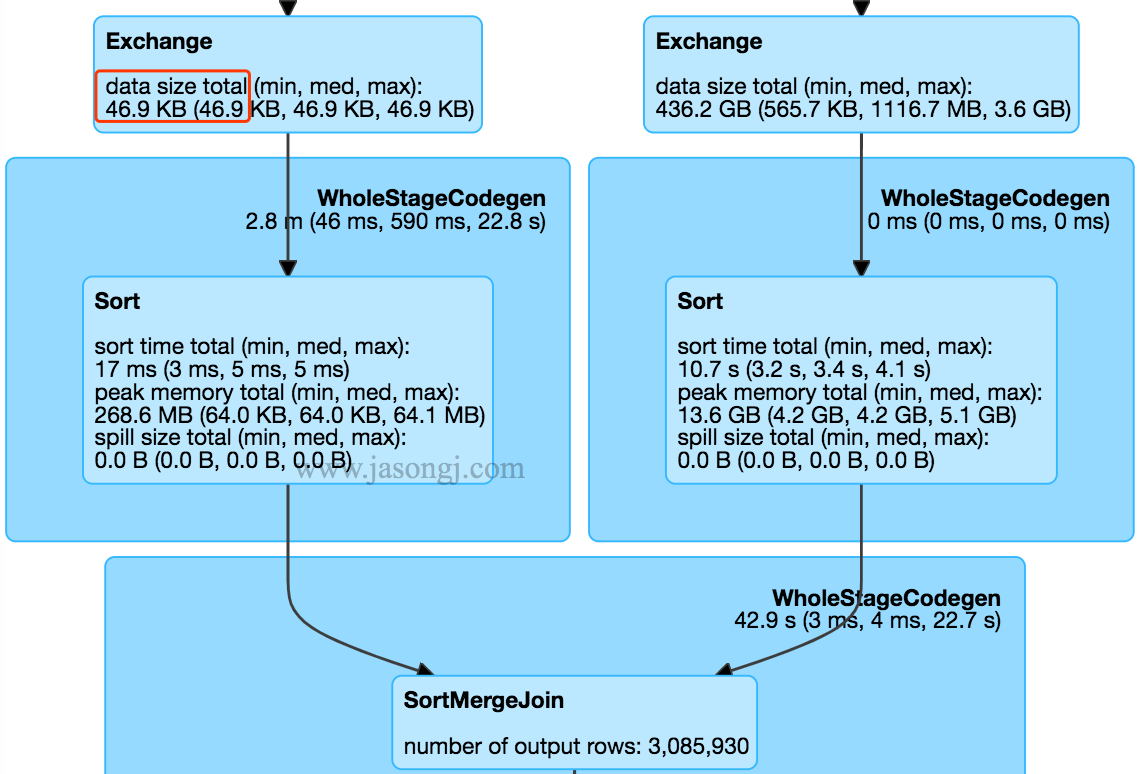
此时完全可将 SortMergeJoin 变更为 BroadcastJoin 从而提高整体执行效率。
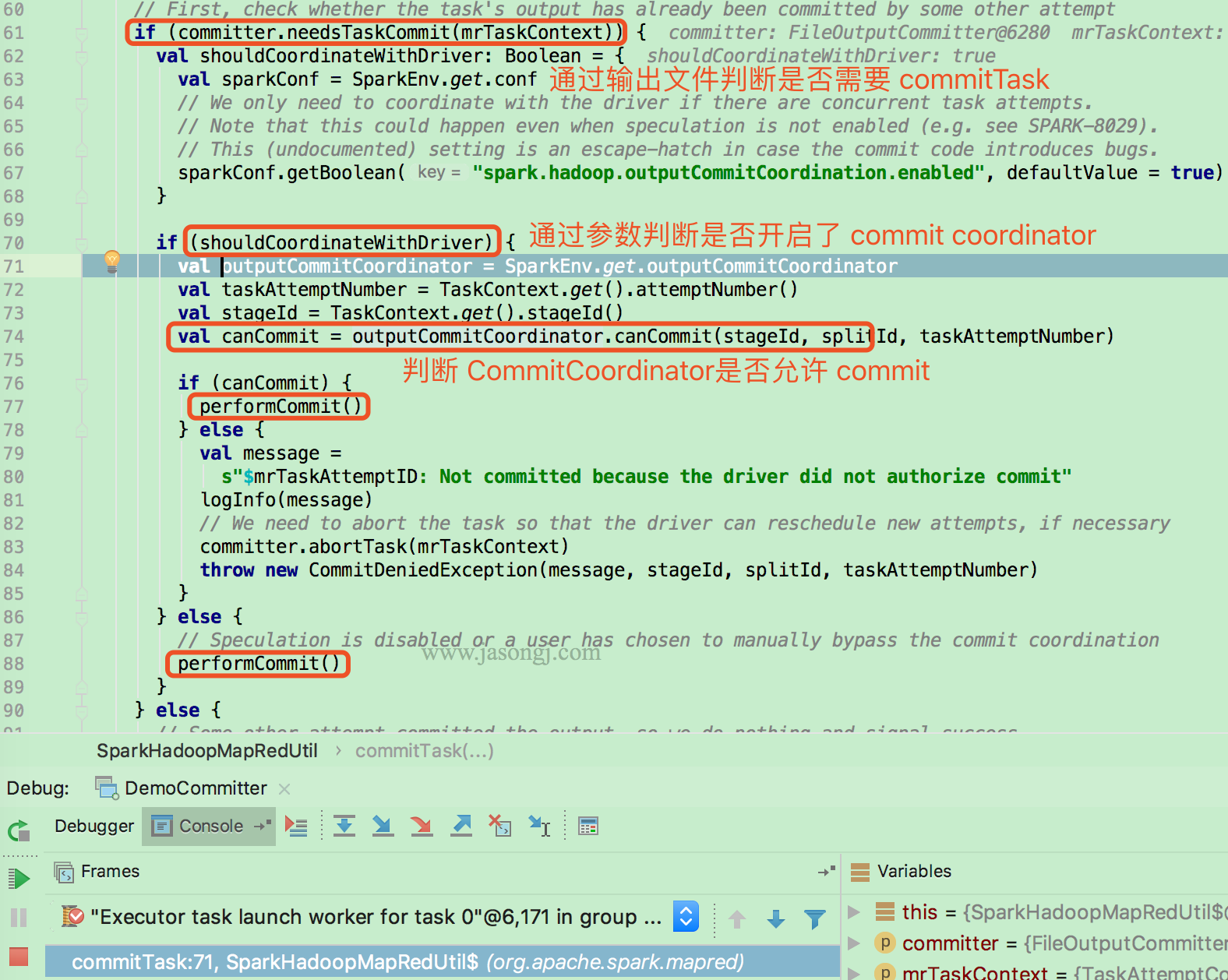
3.2 SortMergeJoin 原理
SortMergeJoin 是常用的分布式 Join 方式,它几乎可使用于所有需要 Join 的场景。但有些场景下,它的性能并不是最好的。
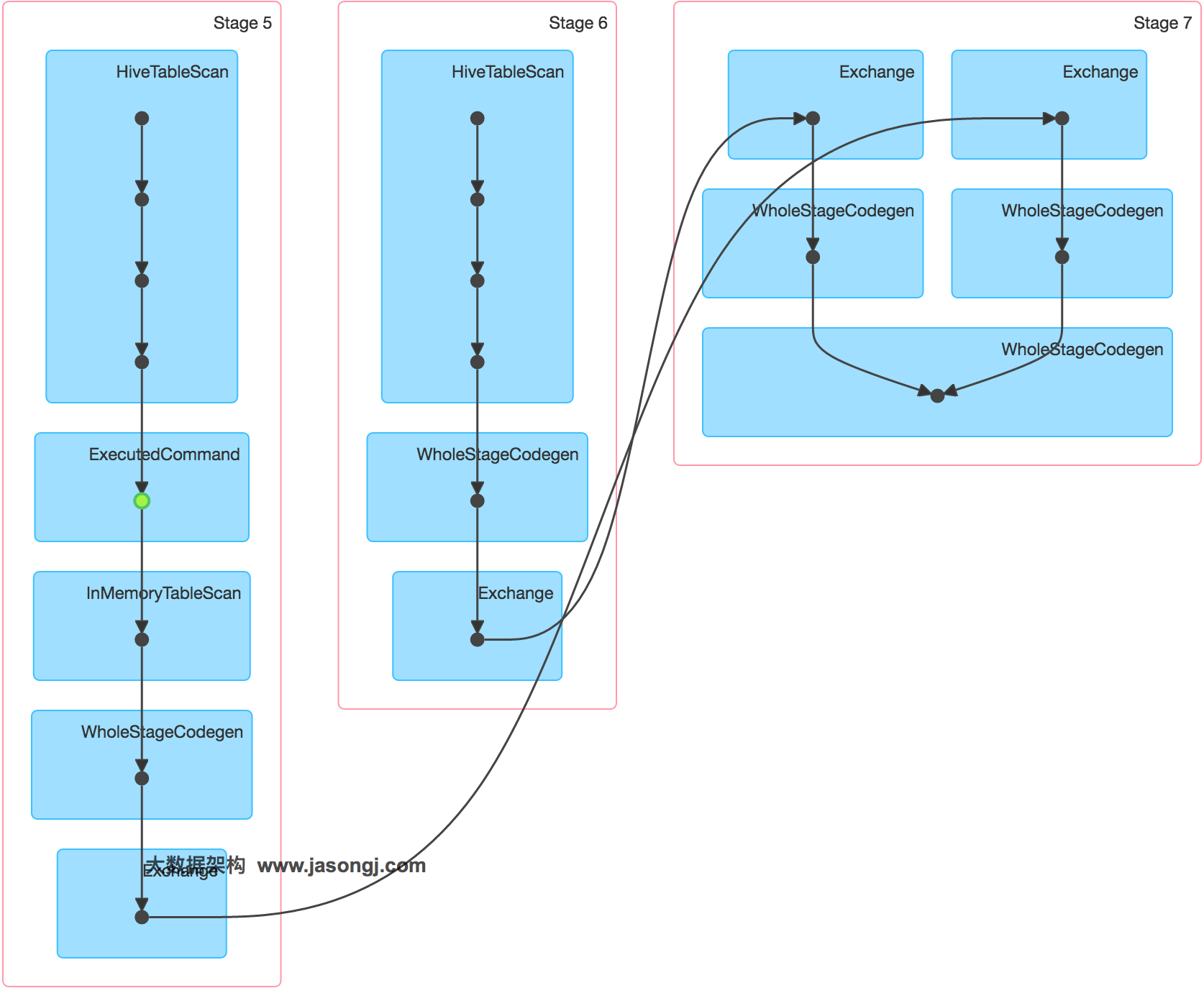
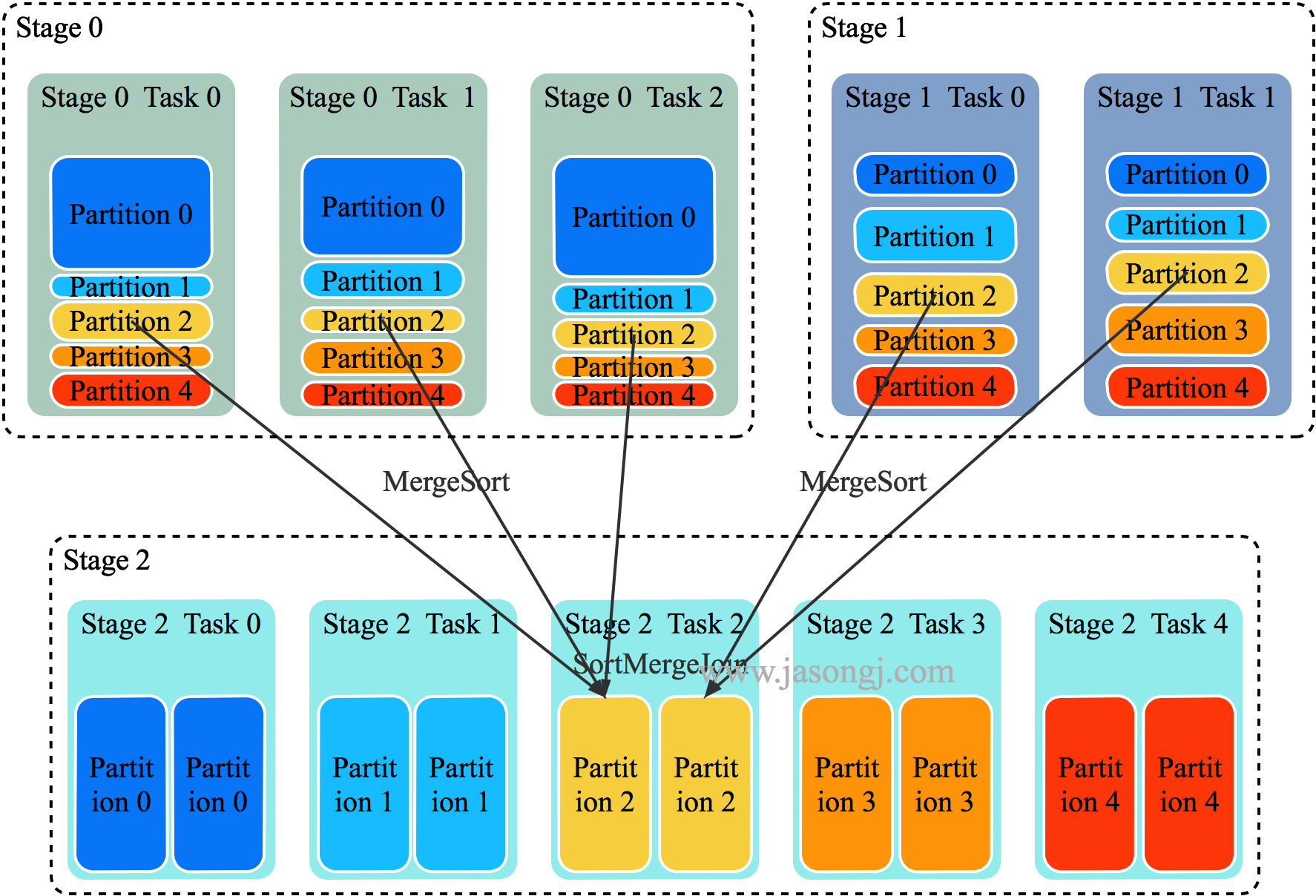
SortMergeJoin 的原理如下图所示
- 将 Join 双方以 Join Key 为 Key 按照 HashPartitioner 分区,且保证分区数一致
- Stage 0 与 Stage 1 的所有 Task 在 Shuffle Write 时,都将数据分为 5 个 Partition,并且每个 Partition 内按 Join Key 排序
- Stage 2 启动 5 个 Task 分别去 Stage 0 与 Stage 1 中所有包含 Partition 分区数据的 Task 中取对应 Partition 的数据。(如果某个 Mapper 不包含该 Partition 的数据,则 Redcuer 无须向其发起读取请求)。
- Stage 2 的 Task 2 分别从 Stage 0 的 Task 0、1、2 中读取 Partition 2 的数据,并且通过 MergeSort 对其进行排序
- Stage 2 的 Task 2 分别从 Stage 1 的 Task 0、1 中读取 Partition 2 的数据,且通过 MergeSort 对其进行排序
- Stage 2 的 Task 2 在上述两步 MergeSort 的同时,使用 SortMergeJoin 对二者进行 Join
3.3 BroadcastJoin 原理
当参与 Join 的一方足够小,可全部置于 Executor 内存中时,可使用 Broadcast 机制将整个 RDD 数据广播到每一个 Executor 中,该 Executor 上运行的所有 Task 皆可直接读取其数据。(本文中,后续配图,为了方便展示,会将整个 RDD 的数据置于 Task 框内,而隐藏 Executor)
对于大 RDD,按正常方式,每个 Task 读取并处理一个 Partition 的数据,同时读取 Executor 内的广播数据,该广播数据包含了小 RDD 的全量数据,因此可直接与每个 Task 处理的大 RDD 的部分数据直接 Join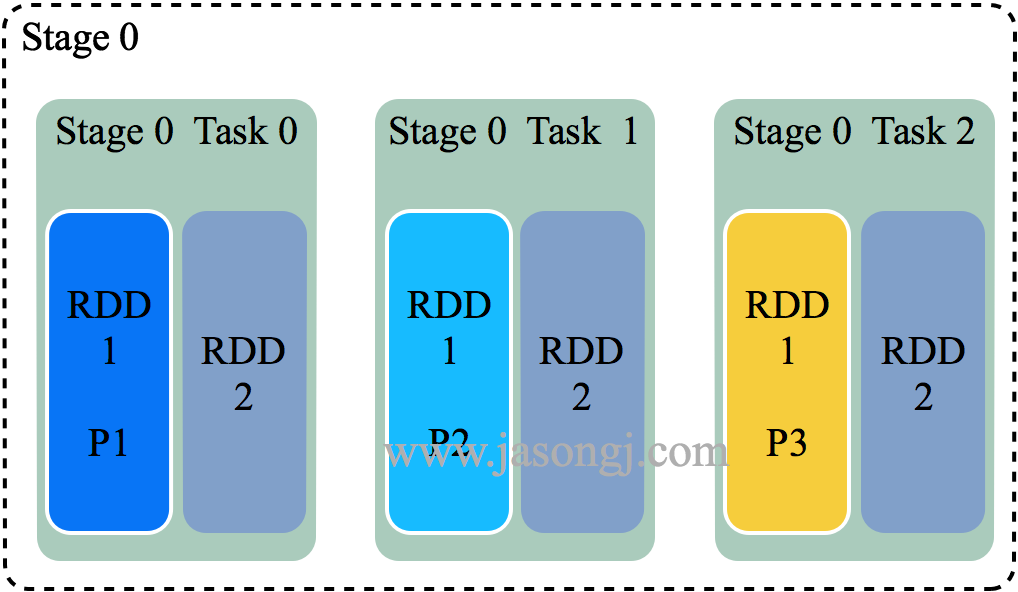
根据 Task 内具体的 Join 实现的不同,又可分为 BroadcastHashJoin 与 BroadcastNestedLoopJoin。后文不区分这两种实现,统称为 BroadcastJoin
与 SortMergeJoin 相比,BroadcastJoin 不需要 Shuffle,减少了 Shuffle 带来的开销,同时也避免了 Shuffle 带来的数据倾斜,从而极大地提升了 Job 执行效率
同时,BroadcastJoin 带来了广播小 RDD 的开销。另外,如果小 RDD 过大,无法存于 Executor 内存中,则无法使用 BroadcastJoin
对于基础表的 Join,可在生成执行计划前,直接通过 HDFS 获取各表的大小,从而判断是否适合使用 BroadcastJoin。但对于中间表的 Join,无法提前准确判断中间表大小从而精确判断是否适合使用 BroadcastJoin
《Spark SQL 性能优化再进一步 CBO 基于代价的优化》一文介绍的 CBO 可通过表的统计信息与各操作对数据统计信息的影响,推测出中间表的统计信息,但是该方法得到的统计信息不够准确。同时该方法要求提前分析表,具有较大开销
而开启 Adaptive Execution 后,可直接根据 Shuffle Write 数据判断是否适用 BroadcastJoin
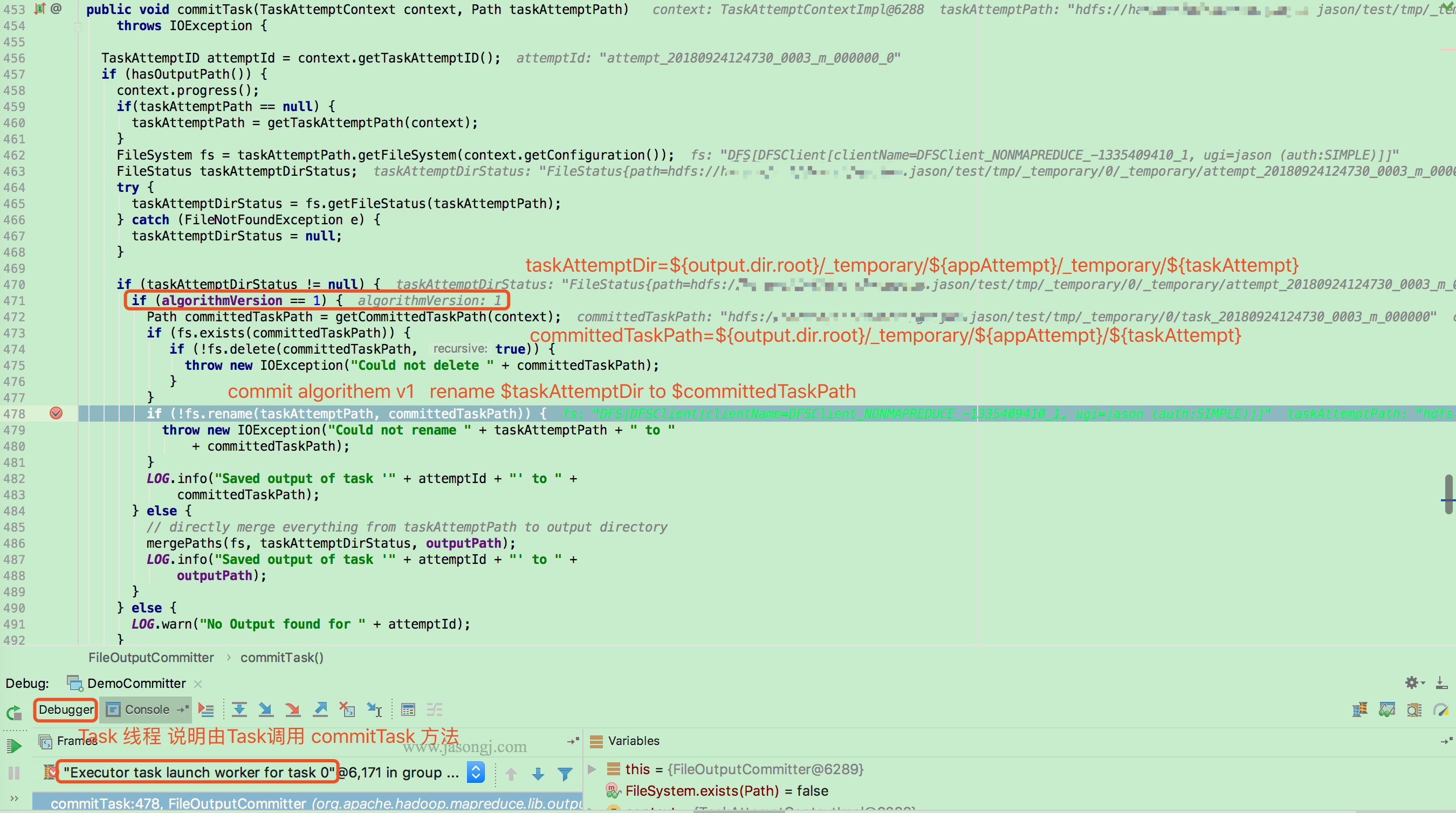
3.4 动态调整执行计划原理
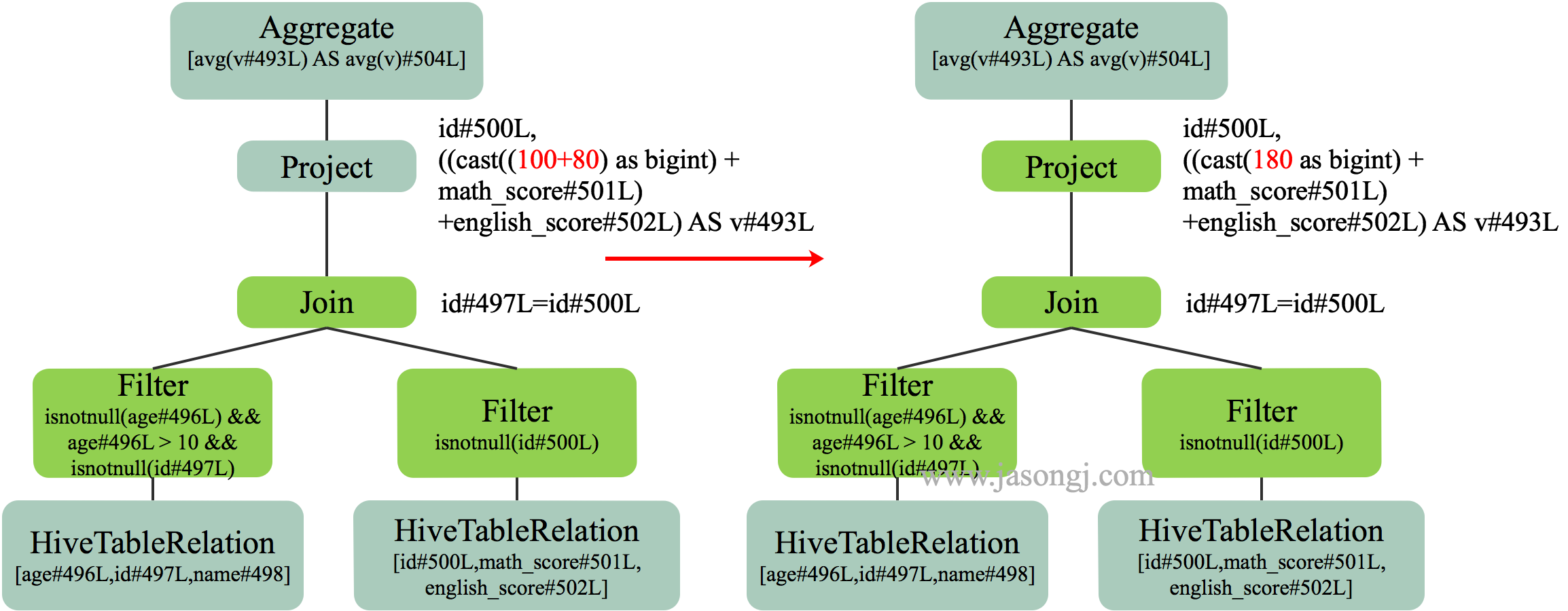
如上文 SortMergeJoin 原理 中配图所示,SortMergeJoin 需要先对 Stage 0 与 Stage 1 按同样的 Partitioner 进行 Shuffle Write
Shuffle Write 结束后,可从每个 ShuffleMapTask 的 MapStatus 中统计得到按原计划执行时 Stage 2 各 Partition 的数据量以及 Stage 2 需要读取的总数据量。(一般来说,Partition 是 RDD 的属性而非 Stage 的属性,本文为了方便,不区分 Stage 与 RDD。可以简单认为一个 Stage 只有一个 RDD,此时 Stage 与 RDD 在本文讨论范围内等价)
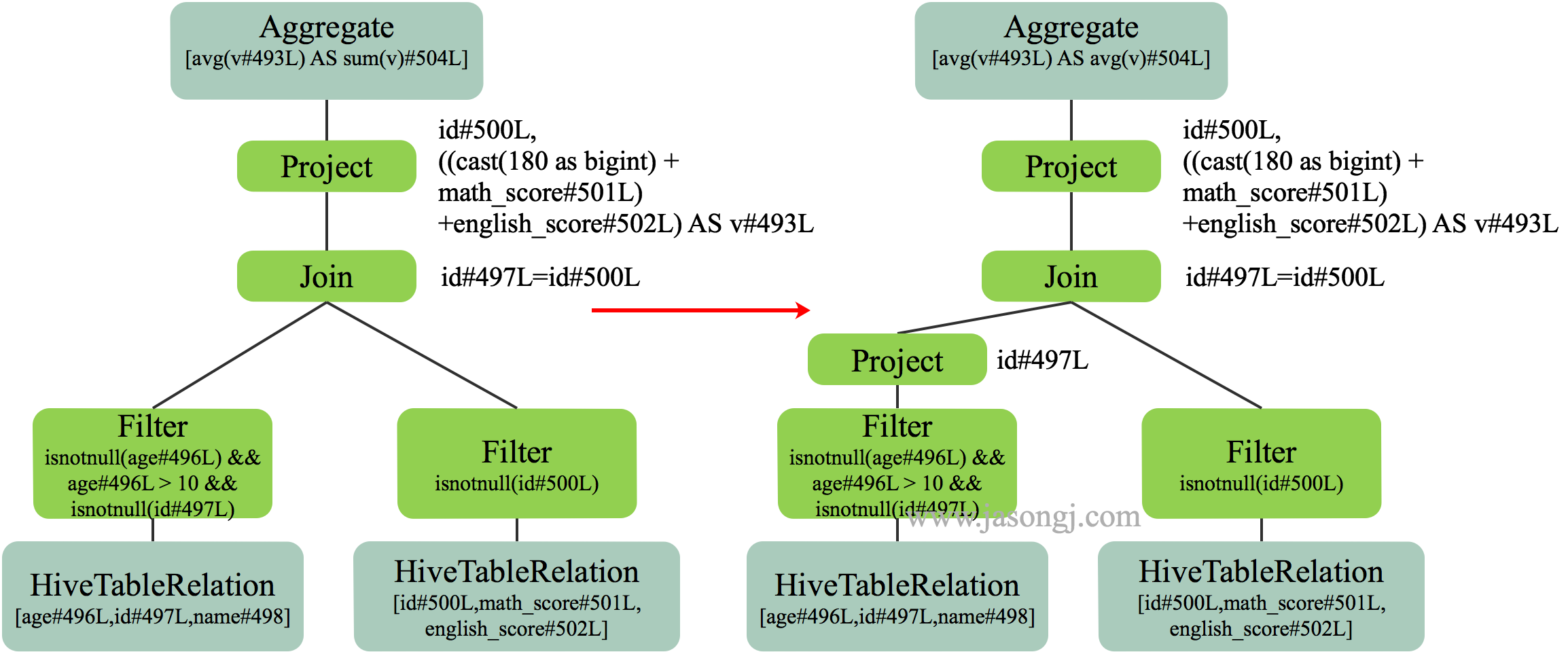
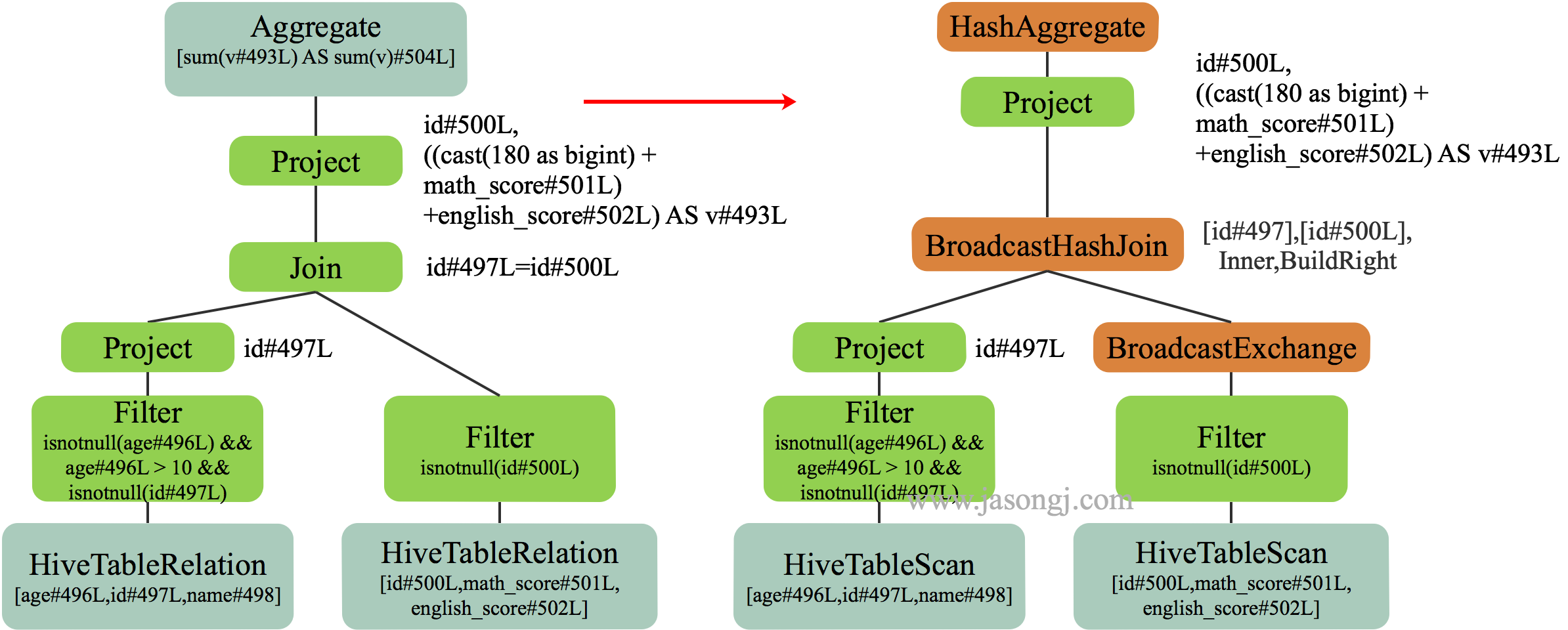
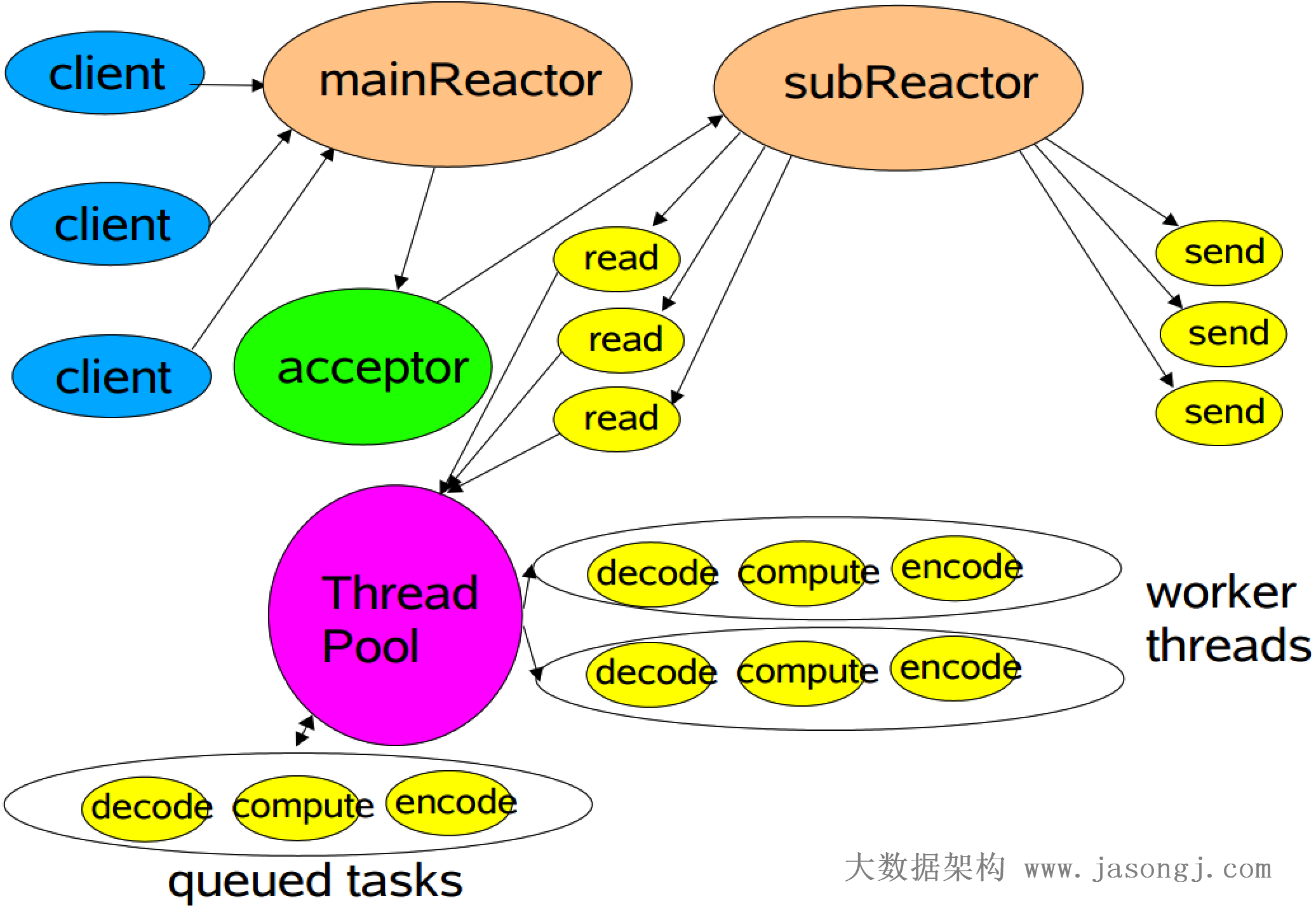
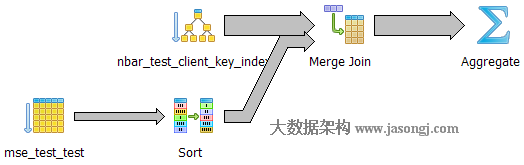
如果其中一个 Stage 的数据量较小,适合使用 BroadcastJoin,无须继续执行 Stage 2 的 Shuffle Read。相反,可利用 Stage 0 与 Stage 1 的数据进行 BroadcastJoin,如下图所示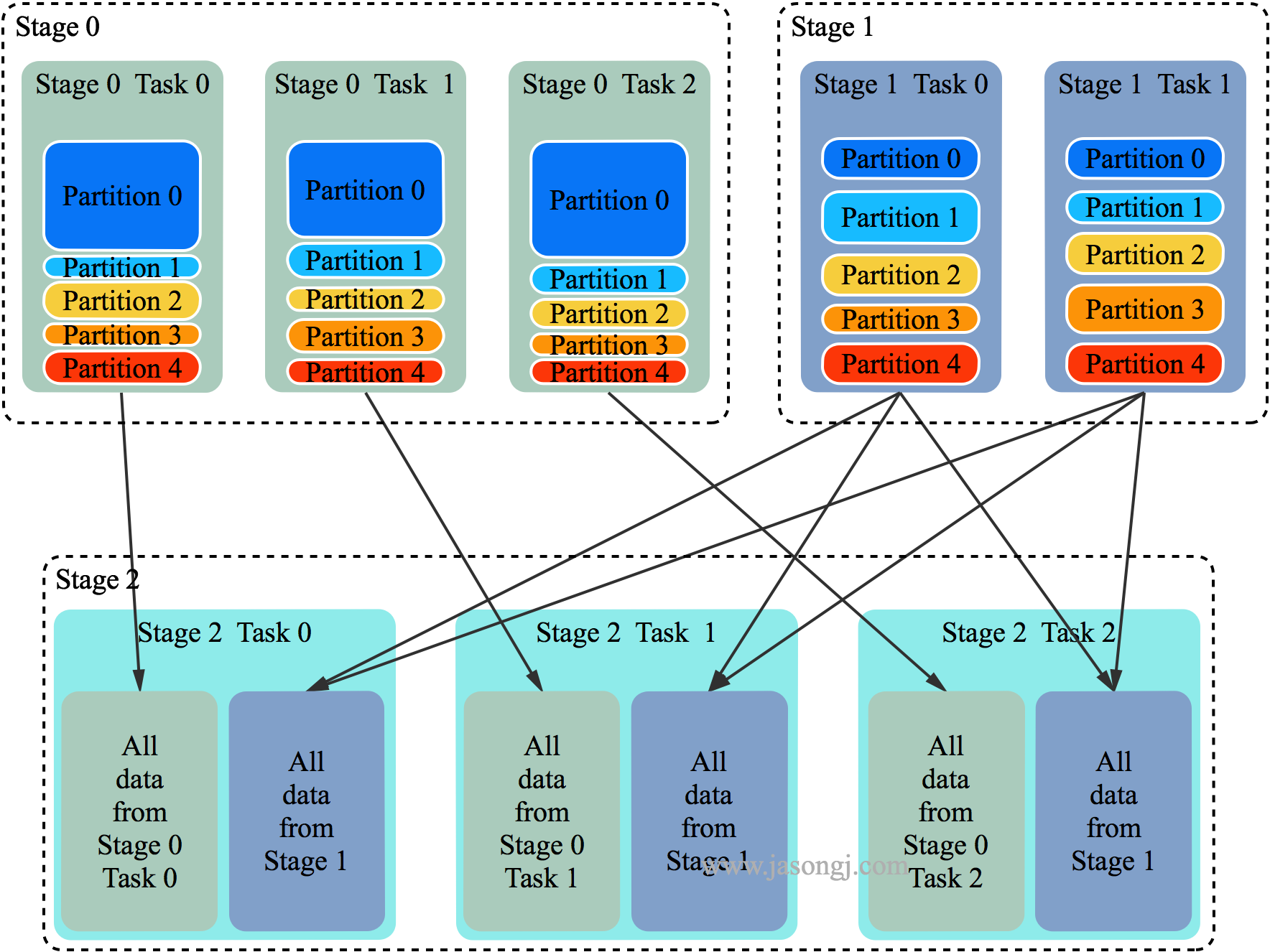
具体做法是
- 将 Stage 1 全部 Shuffle Write 结果广播出去
- 启动 Stage 2,Partition 个数与 Stage 0 一样,都为 3
- 每个 Stage 2 每个 Task 读取 Stage 0 每个 Task 的 Shuffle Write 数据,同时与广播得到的 Stage 1 的全量数据进行 Join
注:广播数据存于每个 Executor 中,其上所有 Task 共享,无须为每个 Task 广播一份数据。上图中,为了更清晰展示为什么能够直接 Join 而将 Stage 2 每个 Task 方框内都放置了一份 Stage 1 的全量数据
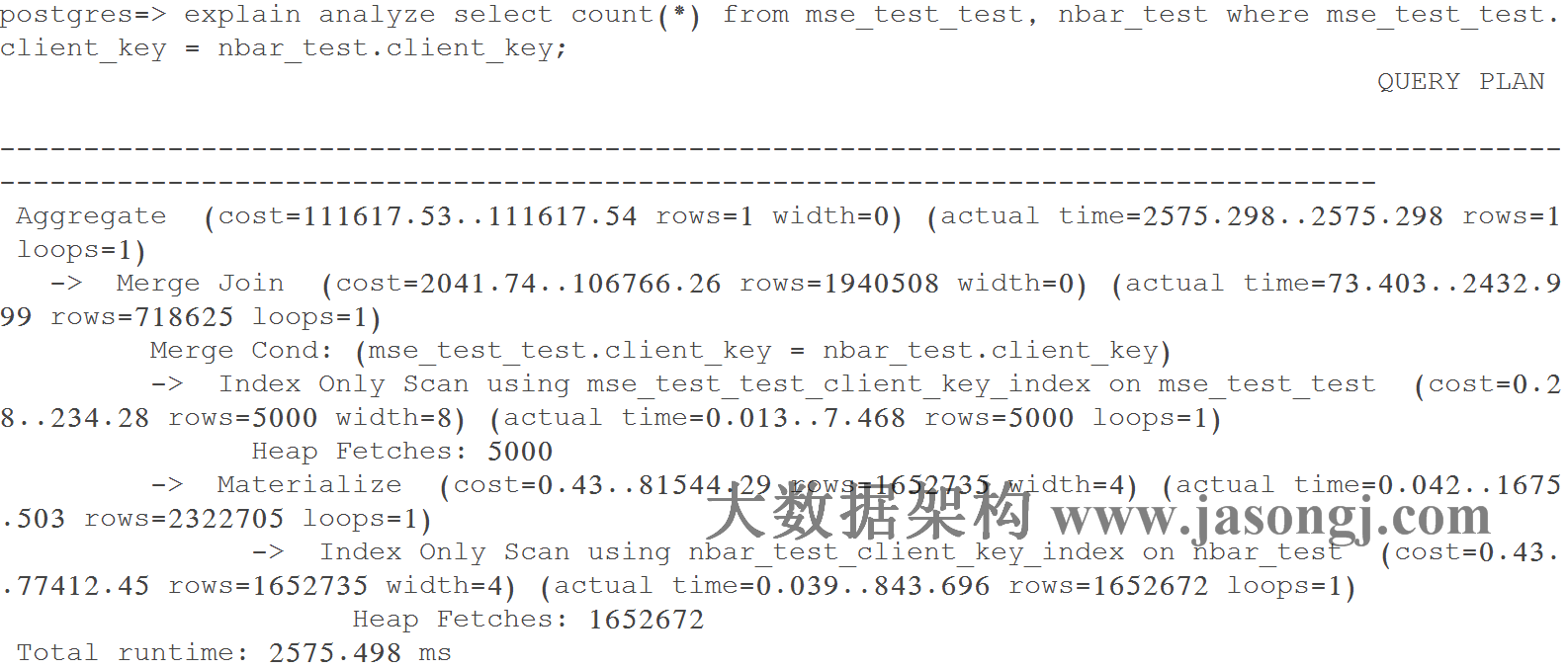
虽然 Shuffle Write 已完成,将后续的 SortMergeJoin 改为 Broadcast 仍然能提升执行效率
- SortMergeJoin 需要在 Shuffle Read 时对来自 Stage 0 与 Stage 1 的数据进行 Merge Sort,并且可能需要 Spill 到磁盘,开销较大
- SortMergeJoin 时,Stage 2 的所有 Task 需要取 Stage 0 与 Stage 1 的所有 Task 的输出数据(如果有它要的数据 ),会造成大量的网络连接。且当 Stage 2 的 Task 较多时,会造成大量的磁盘随机读操作,效率不高,且影响相同机器上其它 Job 的执行效率
- SortMergeJoin 时,Stage 2 每个 Task 需要从几乎所有 Stage 0 与 Stage 1 的 Task 取数据,无法很好利用 Locality
- Stage 2 改用 Broadcast,每个 Task 直接读取 Stage 0 的每个 Task 的数据(一对一),可很好利用 Locality 特性。最好在 Stage 0 使用的 Executor 上直接启动 Stage 2 的 Task。如果 Stage 0 的 Shuffle Write 数据并未 Spill 而是在内存中,则 Stage 2 的 Task 可直接读取内存中的数据,效率非常高。如果有 Spill,那可直接从本地文件中读取数据,且是顺序读取,效率远比通过网络随机读数据效率高
3.5 使用与优化方法
该特性的使用方式如下
- 当
spark.sql.adaptive.enabled与spark.sql.adaptive.join.enabled都设置为true时,开启 Adaptive Execution 的动态调整 Join 功能 spark.sql.adaptiveBroadcastJoinThreshold设置了 SortMergeJoin 转 BroadcastJoin 的阈值。如果不设置该参数,该阈值与spark.sql.autoBroadcastJoinThreshold的值相等- 除了本文所述 SortMergeJoin 转 BroadcastJoin,Adaptive Execution 还可提供其它 Join 优化策略。部分优化策略可能会需要增加 Shuffle。
spark.sql.adaptive.allowAdditionalShuffle参数决定了是否允许为了优化 Join 而增加 Shuffle。其默认值为 false
4 自动处理数据倾斜
4.1 解决数据倾斜典型方案
《Spark性能优化之道——解决Spark数据倾斜(Data Skew)的N种姿势》一文讲述了数据倾斜的危害,产生原因,以及典型解决方法
- 保证文件可 Split 从而避免读 HDFS 时数据倾斜
- 保证 Kafka 各 Partition 数据均衡从而避免读 Kafka 引起的数据倾斜
- 调整并行度或自定义 Partitioner 从而分散分配给同一 Task 的大量不同 Key
- 使用 BroadcastJoin 代替 ReduceJoin 消除 Shuffle 从而避免 Shuffle 引起的数据倾斜
- 对倾斜 Key 使用随机前缀或后缀从而分散大量倾斜 Key,同时将参与 Join 的小表扩容,从而保证 Join 结果的正确性
4.2 自动解决数据倾斜
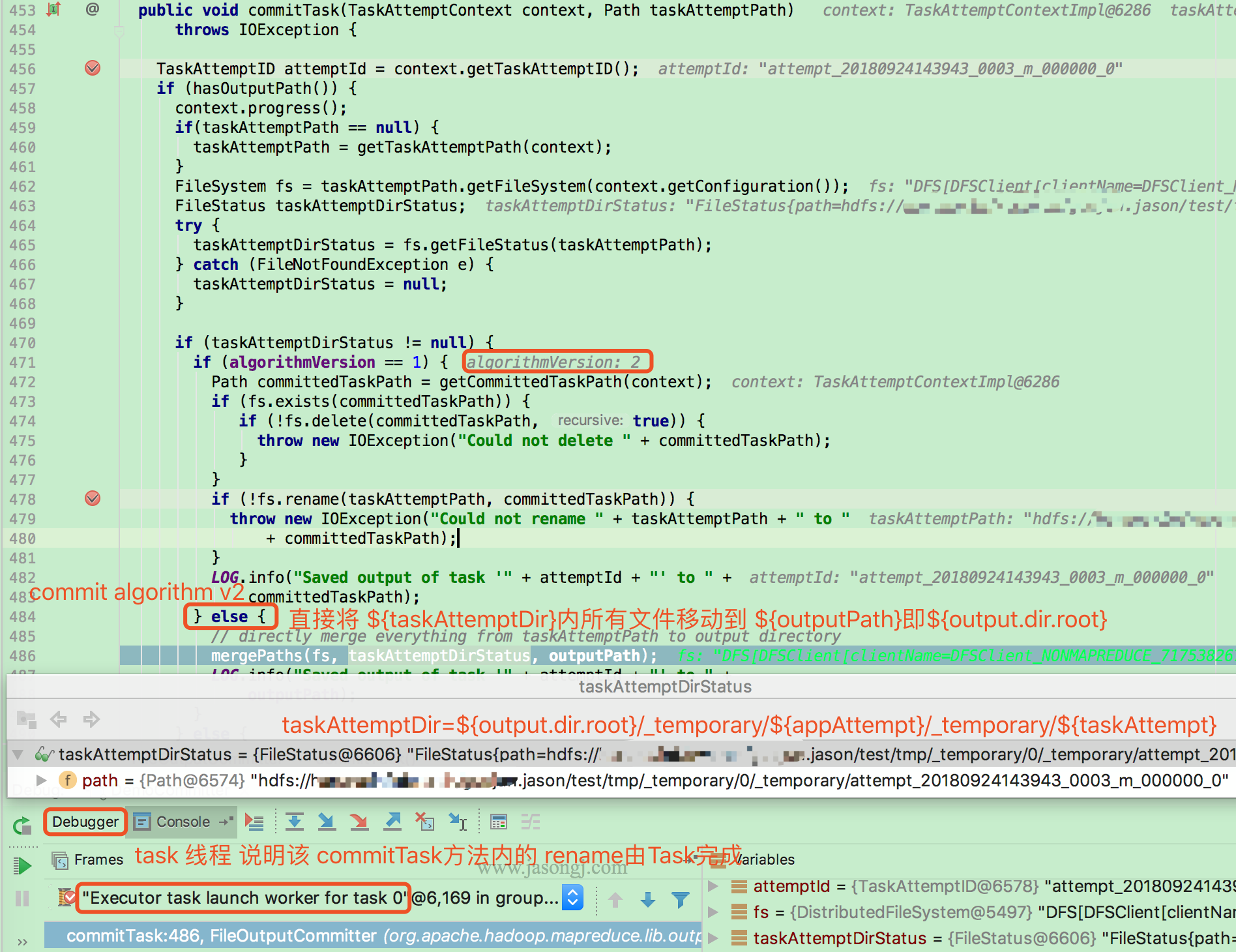
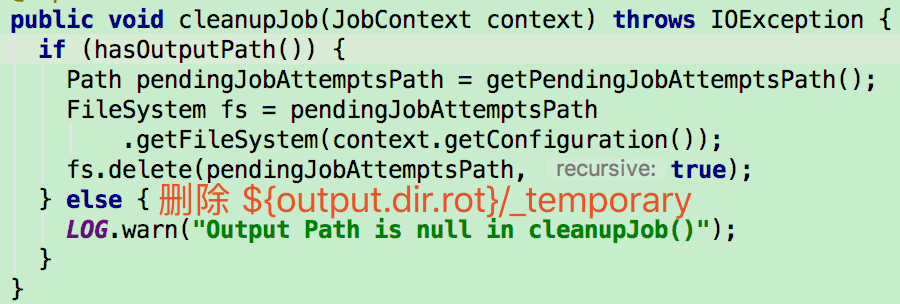
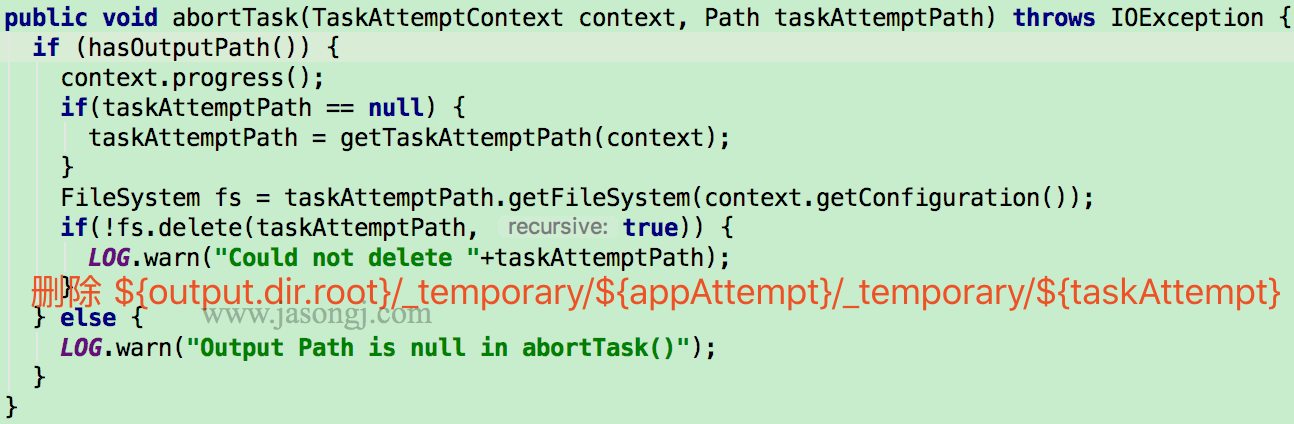
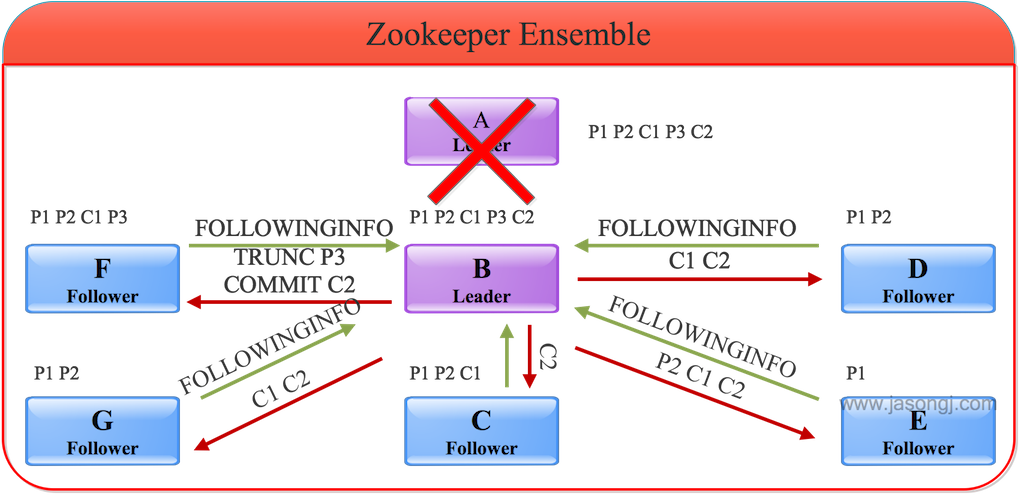
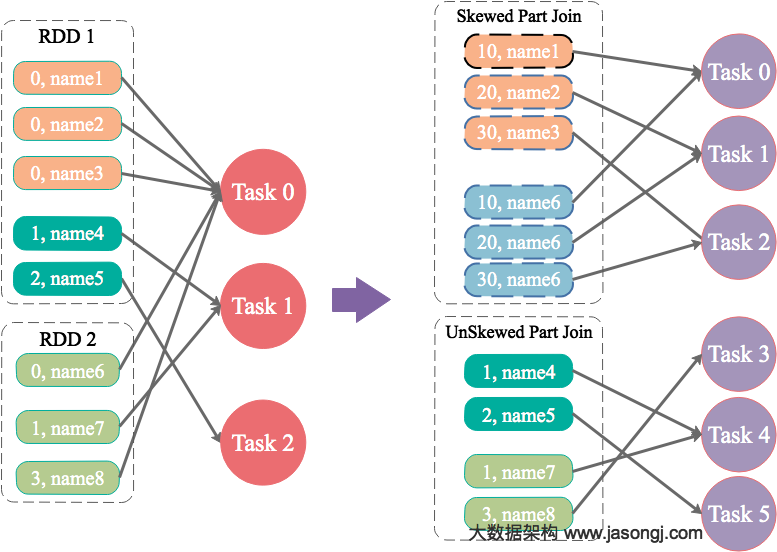
目前 Adaptive Execution 可解决 Join 时数据倾斜问题。其思路可理解为将部分倾斜的 Partition (倾斜的判断标准为该 Partition 数据是所有 Partition Shuffle Write 中位数的 N 倍) 进行单独处理,类似于 BroadcastJoin,如下图所示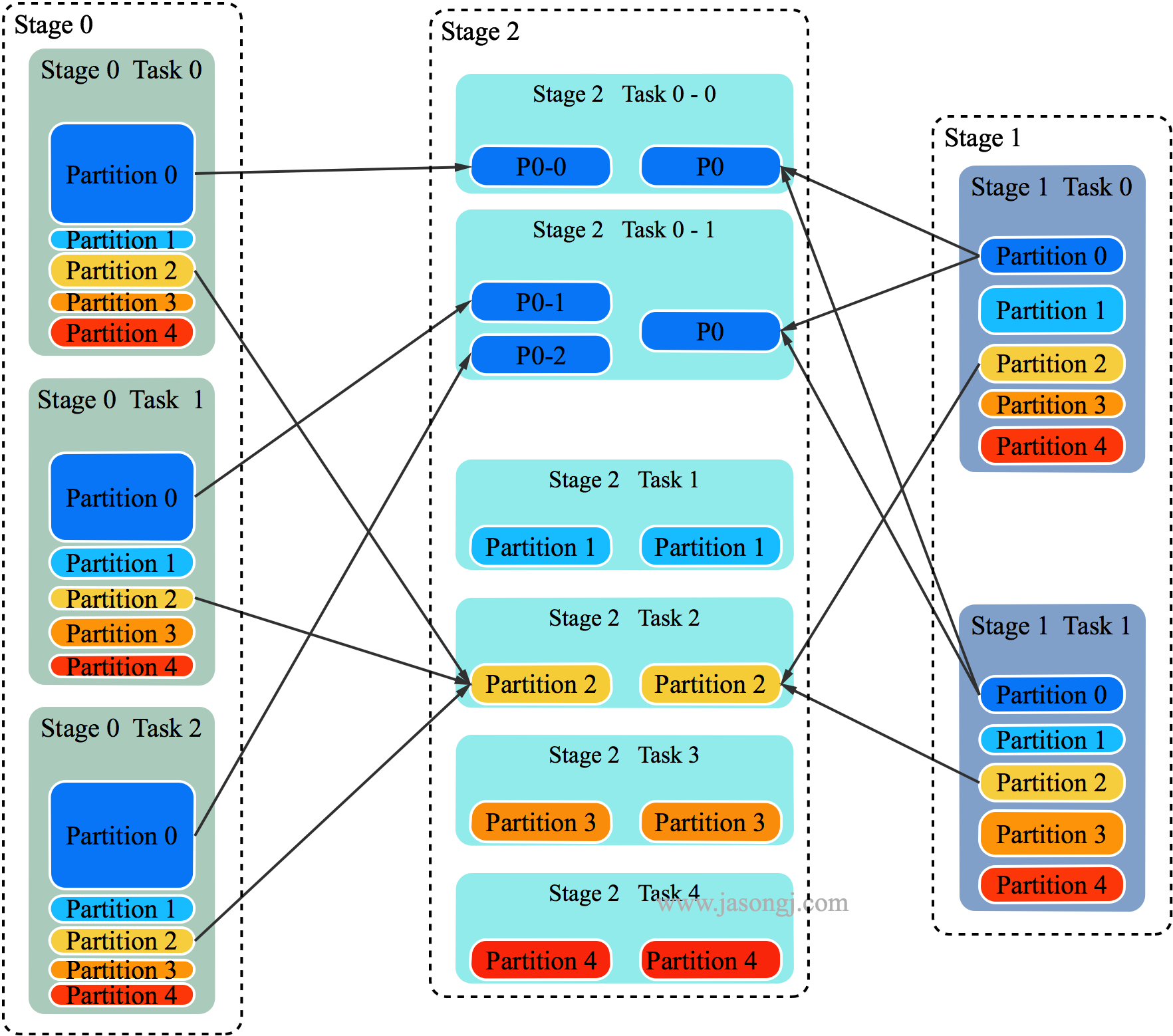
在上图中,左右两边分别是参与 Join 的 Stage 0 与 Stage 1 (实际应该是两个 RDD 进行 Join,但如同上文所述,这里不区分 RDD 与 Stage),中间是获取 Join 结果的 Stage 2
明显 Partition 0 的数据量较大,这里假设 Partition 0 符合“倾斜”的条件,其它 4 个 Partition 未倾斜
以 Partition 对应的 Task 2 为例,它需获取 Stage 0 的三个 Task 中所有属于 Partition 2 的数据,并使用 MergeSort 排序。同时获取 Stage 1 的两个 Task 中所有属于 Partition 2 的数据并使用 MergeSort 排序。然后对二者进行 SortMergeJoin
对于 Partition 0,可启动多个 Task
- 在上图中,启动了两个 Task 处理 Partition 0 的数据,分别名为 Task 0-0 与 Task 0-1
- Task 0-0 读取 Stage 0 Task 0 中属于 Partition 0 的数据
- Task 0-1 读取 Stage 0 Task 1 与 Task 2 中属于 Partition 0 的数据,并进行 MergeSort
- Task 0-0 与 Task 0-1 都从 Stage 1 的两个 Task 中所有属于 Partition 0 的数据
- Task 0-0 与 Task 0-1 使用 Stage 0 中属于 Partition 0 的部分数据与 Stage 1 中属于 Partition 0 的全量数据进行 Join
通过该方法,原本由一个 Task 处理的 Partition 0 的数据由多个 Task 共同处理,每个 Task 需处理的数据量减少,从而避免了 Partition 0 的倾斜
对于 Partition 0 的处理,有点类似于 BroadcastJoin 的做法。但区别在于,Stage 2 的 Task 0-0 与 Task 0-1 同时获取 Stage 1 中属于 Partition 0 的全量数据,是通过正常的 Shuffle Read 机制实现,而非 BroadcastJoin 中的变量广播实现
4.3 使用与优化方法
开启与调优该特性的方法如下
- 将
spark.sql.adaptive.skewedJoin.enabled设置为 true 即可自动处理 Join 时数据倾斜 spark.sql.adaptive.skewedPartitionMaxSplits控制处理一个倾斜 Partition 的 Task 个数上限,默认值为 5spark.sql.adaptive.skewedPartitionRowCountThreshold设置了一个 Partition 被视为倾斜 Partition 的行数下限,也即行数低于该值的 Partition 不会被当作倾斜 Partition 处理。其默认值为 10L * 1000 * 1000 即一千万spark.sql.adaptive.skewedPartitionSizeThreshold设置了一个 Partition 被视为倾斜 Partition 的大小下限,也即大小小于该值的 Partition 不会被视作倾斜 Partition。其默认值为 64 * 1024 * 1024 也即 64MBspark.sql.adaptive.skewedPartitionFactor该参数设置了倾斜因子。如果一个 Partition 的大小大于spark.sql.adaptive.skewedPartitionSizeThreshold的同时大于各 Partition 大小中位数与该因子的乘积,或者行数大于spark.sql.adaptive.skewedPartitionRowCountThreshold的同时大于各 Partition 行数中位数与该因子的乘积,则它会被视为倾斜的 Partition