原创文章,转载请务必将下面这段话置于文章开头处(保留超链接)。
本文转发自技术世界,原文链接 http://www.jasongj.com/2015/03/07/Join1/
Nested Loop,Hash Join,Merge Join介绍
Nested Loop:
对于被连接的数据子集较小的情况,Nested Loop是个较好的选择。Nested Loop就是扫描一个表(外表),每读到一条记录,就根据Join字段上的索引去另一张表(内表)里面查找,若Join字段上没有索引查询优化器一般就不会选择 Nested Loop。在Nested Loop中,内表(一般是带索引的大表)被外表(也叫“驱动表”,一般为小表——不紧相对其它表为小表,而且记录数的绝对值也较小,不要求有索引)驱动,外表返回的每一行都要在内表中检索找到与它匹配的行,因此整个查询返回的结果集不能太大(大于1 万不适合)。Hash Join:
Hash Join是做大数据集连接时的常用方式,优化器使用两个表中较小(相对较小)的表利用Join Key在内存中建立散列表,然后扫描较大的表并探测散列表,找出与Hash表匹配的行。
这种方式适用于较小的表完全可以放于内存中的情况,这样总成本就是访问两个表的成本之和。但是在表很大的情况下并不能完全放入内存,这时优化器会将它分割成若干不同的分区,不能放入内存的部分就把该分区写入磁盘的临时段,此时要求有较大的临时段从而尽量提高I/O 的性能。它能够很好的工作于没有索引的大表和并行查询的环境中,并提供最好的性能。大多数人都说它是Join的重型升降机。Hash Join只能应用于等值连接(如WHERE A.COL3 = B.COL4),这是由Hash的特点决定的。Merge Join:
通常情况下Hash Join的效果都比排序合并连接要好,然而如果两表已经被排过序,在执行排序合并连接时不需要再排序了,这时Merge Join的性能会优于Hash Join。Merge join的操作通常分三步:
1. 对连接的每个表做table access full;
2. 对table access full的结果进行排序。
3. 进行merge join对排序结果进行合并。
在全表扫描比索引范围扫描再进行表访问更可取的情况下,Merge Join会比Nested Loop性能更佳。当表特别小或特别巨大的时候,实行全表访问可能会比索引范围扫描更有效。Merge Join的性能开销几乎都在前两步。Merge Join可适于于非等值Join(>,<,>=,<=,但是不包含!=,也即<>)
Nested Loop,Hash JOin,Merge Join对比
| 类别 | Nested Loop | Hash Join | Merge Join |
|---|---|---|---|
| 使用条件 | 任何条件 | 等值连接(=) | 等值或非等值连接(>,<,=,>=,<=),‘<>’除外 |
| 相关资源 | CPU、磁盘I/O | 内存、临时空间 | 内存、临时空间 |
| 特点 | 当有高选择性索引或进行限制性搜索时效率比较高,能够快速返回第一次的搜索结果。 | 当缺乏索引或者索引条件模糊时,Hash Join比Nested Loop有效。通常比Merge Join快。在数据仓库环境下,如果表的纪录数多,效率高。 | 当缺乏索引或者索引条件模糊时,Merge Join比Nested Loop有效。非等值连接时,Merge Join比Hash Join更有效 |
| 缺点 | 当索引丢失或者查询条件限制不够时,效率很低;当表的纪录数多时,效率低。 | 为建立哈希表,需要大量内存。第一次的结果返回较慢。 | 所有的表都需要排序。它为最优化的吞吐量而设计,并且在结果没有全部找到前不返回数据。 |
实验
本文所做实验均基于PostgreSQL 9.3.5平台
小于万条记录小表与大表Join
一张记录数1万以下的小表nbar.mse_test_test,一张大表165万条记录的大表nbar.nbar_test,大表上建有索引
Query 1:等值Join
1 | select |
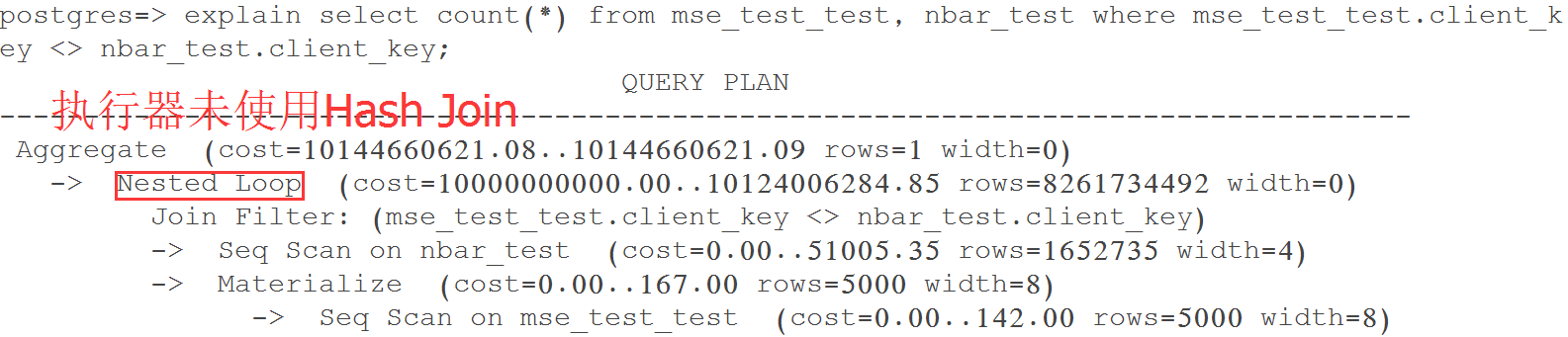
Query 1 Test 1: 查询优化器自动选择Nested Loop,耗时784.845 ms

如下图所示,执行器将小表mse_test_test作为外表(驱动表),对于其中的每条记录,通过大表(nbar_test)上的索引匹配相应记录。
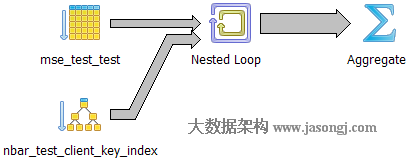
Query 1 Test 2:强制使用Hash Join,耗时1731.836ms

如下图所示,执行器选择一张表将其映射成散列表,再遍历另外一张表并从散列表中匹配相应记录。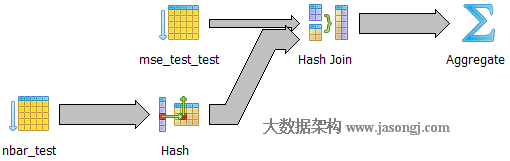
Query 1 Test 3:强制使用Merge Join,耗时4956.768 ms
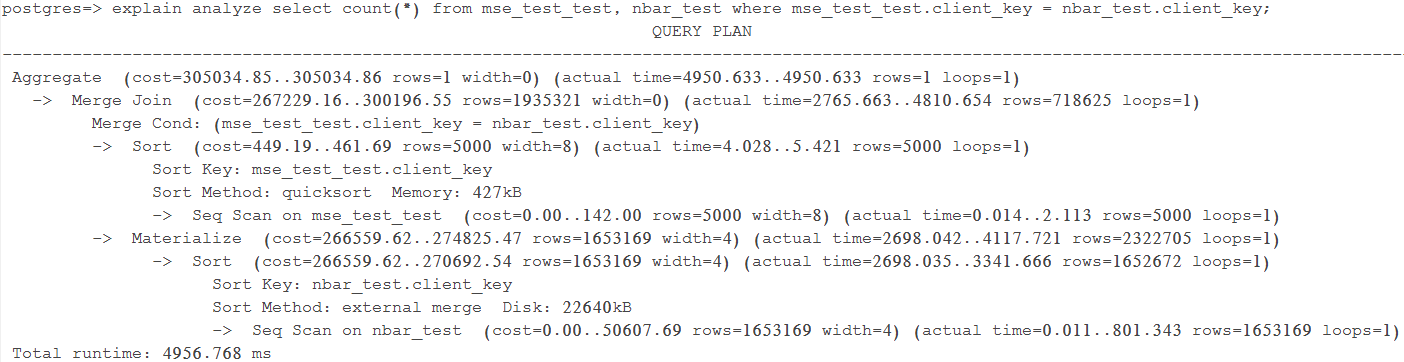
如下图所示,执行器先分别对mse_test_test和nbar_test按client_key排序。其中mse_test_test使用快速排序,而nbar_test使用external merge排序,之后对二者进行Merge Join。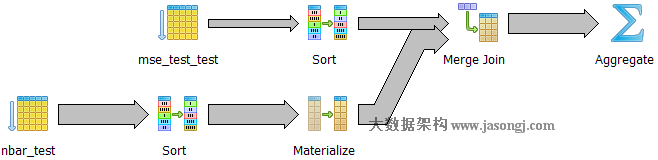
Query 1 总结 1 :
通过对比Query 1 Test 1,Query 1 Test 2,Query 1 Test 3可以看出Nested Loop适用于结果集很小(一般要求小于一万条),并且内表在Join字段上建有索引(这点非常非常非常重要)。
- 在大表上创建聚簇索引
Query 1 Test 4:强制使用Merge Join,耗时1660.228 ms
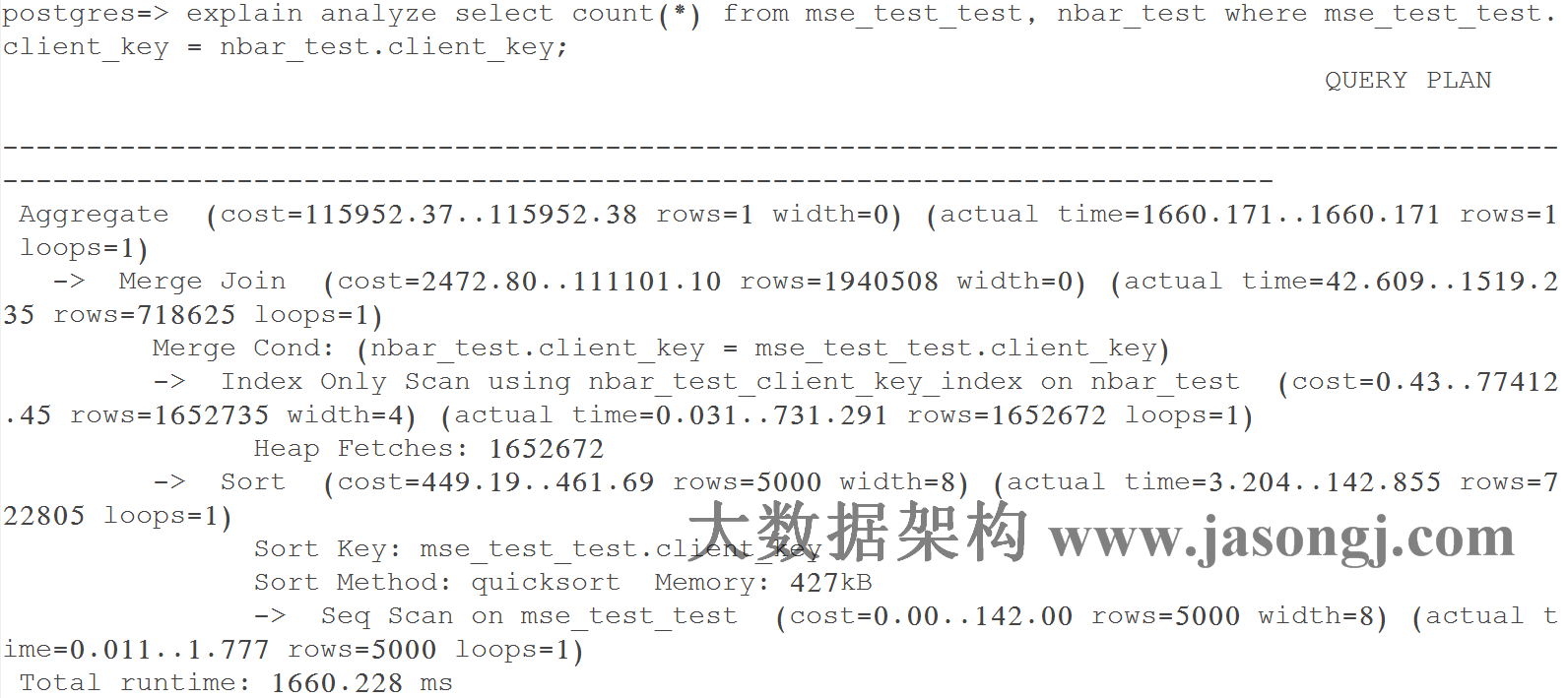
如下图所示,执行器通过聚簇索引对大表(nbar_test)排序,直接通过快排对无索引的小表(mse_test_test)排序,之后对二才进行Merge Join。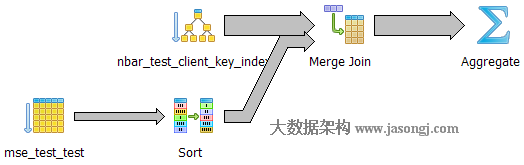
Query 1 总结 2:
通过对比Query 1 Test 3和Query 1 Test 4可以看出,Merge Join的主要开销是排序开销,如果能通过建立聚簇索引(如果Query必须显示排序),可以极大提高Merge Join的性能。从这两个实验可以看出,创建聚簇索引后,查询时间从4956.768 ms缩减到了1815.238 ms。
- 在两表上同时创建聚簇索引
Query 1 Test 5:强制使用Merge Join,耗时2575.498 ms。
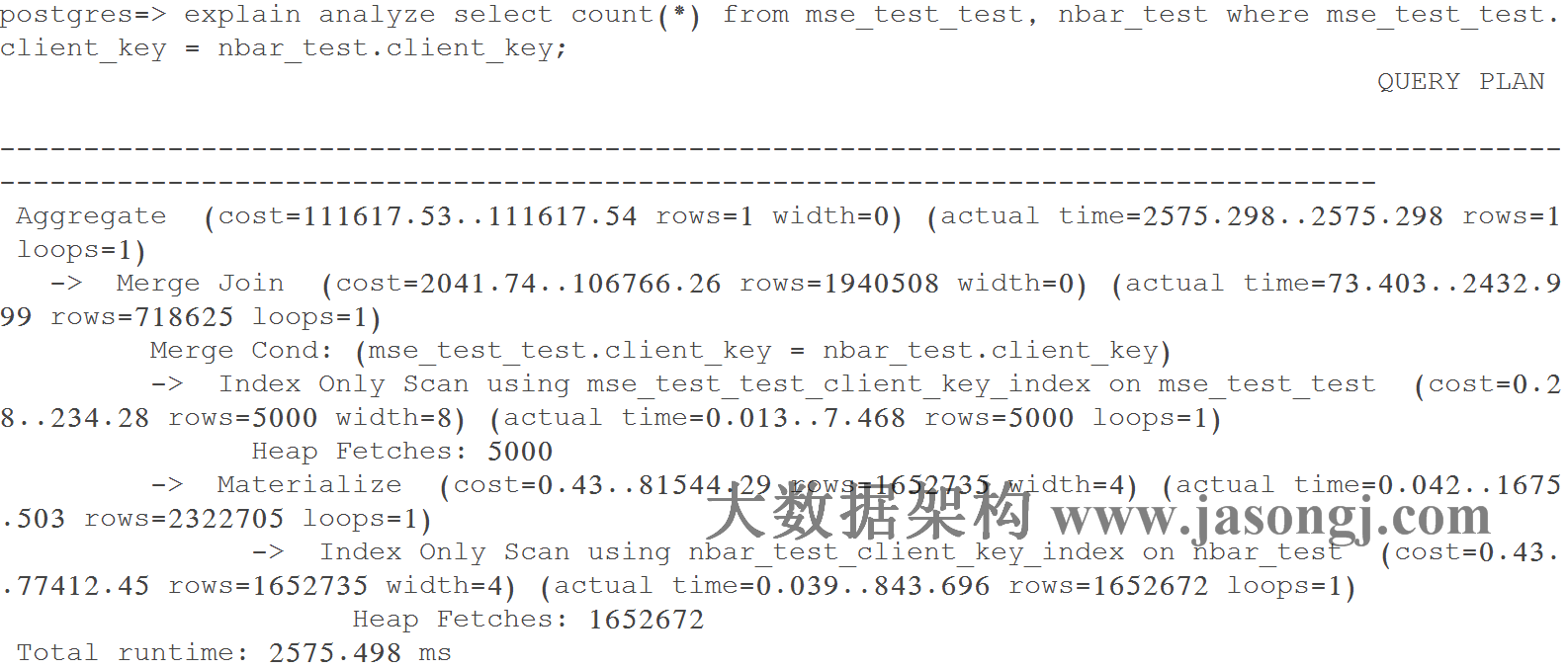
如下图所示,执行器通过聚簇索引对大表(nbar_test)和小表(mse_test_test)排序,之后才进行Merge Join。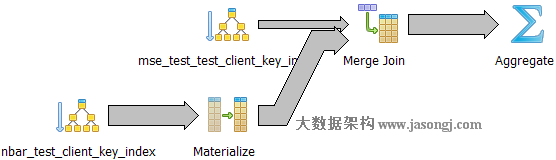
Query 1 总结 3:
对比Query 1 Test 4和Query 1 Test 5,可以看出二者唯一的不同在于对小表(mse_test_test)的访问方式不同,前者使用快排,后者因为聚簇索引的存在而使用Index Only Scan,在表数据量比较小的情况下前者比后者效率更高。由此可看出如果通过索引排序再查找相应的记录比直接在原记录上排序效率还低,则直接在原记录上排序后Merge Join效率更高。
删除nbar_test上的索引
Query 1 Test 6:强制使用Hash Join,耗时1815.238 ms
时间与
Query 1 Test 2几乎相等。
如下图所示,与
Query 1 Test 2相同,执行器选择一张表将其映射成散列表,再遍历另外一张表并从散列表中匹配相应记录。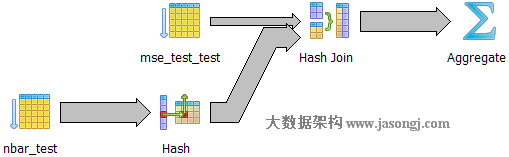
Query 1 总结 4 :
通过对比Query 1 Test 2,Query 1 Test 6可以看出Hash Join不要求表在Join字段上建立索引。
两大表Join
mse_test约100万条记录,nbar_test约165万条记录
###Query 2:不等值Join1
2
3
4
5
6
7
8
9 select
count(*)
from
mse_test,
nbar_test
where
mse_test.client_key = nbar_test.client_key
and
mse_test.client_key between 100000 and 300000;
Query 2 Test 1:强制使用Hash Join,失败
本次实验通过设置enable_hashjoin=true,enable_nestloop=false,enable_mergejoin=false来试图强制使用Hash Join,但是失败了。